[오늘의 일지]
머신러닝 실시간 강의 - 예측 모델 개발 및 적용
[상세 내용]
ML PJT Workflow

예측 모델 개발 및 적용
예측 모델 개발 과정
- 규칙 → 통계 → ML → DL
모델 학습 및 평가
- 주어진 데이터로 모델을 학습시키는 것은 지정한 성능 평가 지표를 향상시키는 과정입니다.
- 데이터를 학습 데이터와 검증 및 테스트 데이터로 나누는 과정이 필요합니다.
- 정량적 기준을 설정하고, 달성할 때까지 모델을 학습시키고 성능을 개선합니다.
- 목표한 성능에 도달한 모델을 실제 서비스에 적용합니다.
모델 성능 개선 전략
Main Skills for Data Scientist

Hyper-parameter tuning

Grid Search vs Random Search
- Random Search를 사용하면 range와 n_trials를 조절해서 accuracy를 높일 수 있다

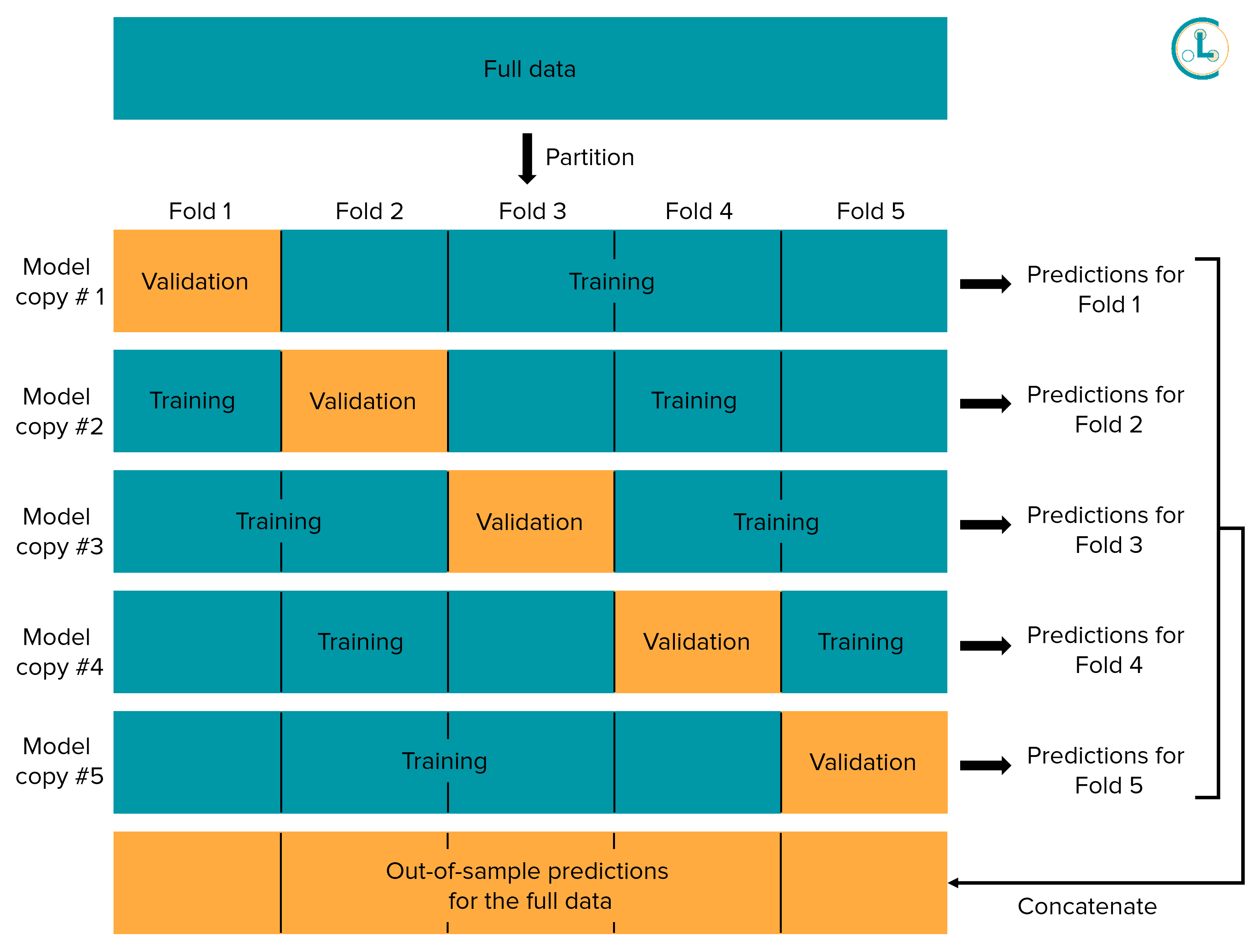
K-Fold Cross Validation
- Out-of-Fold Prediction (OOF)은 K-Fold Cross Validation의 한 부분으로, 각 폴드에서 모델을 평가할 때 생성되는 중간 결과물입니다.
Random Search + Bayesian Optimization = Optuna (AutoML Framework)
- Optuna는 모델의 하이퍼파라미터 (예: 학습률, 은닉층 수, 배치 크기 등)를 최적화하는 데 사용됩니다.
- Optuna는 하이퍼파라미터 공간을 자동으로 탐색하고, 효과적인 하이퍼파라미터를 발견하기 위해 알고리즘을 사용합니다.
- TPE (Tree-structured Parzen Estimator) 및 Random Search와 같은 탐색 알고리즘을 지원합니다.
- 다양한 머신러닝 프레임워크와 통합이 가능합니다. 예를 들어, Scikit-learn, PyTorch, TensorFlow, XGBoost 등과 함께 사용할 수 있습니다.
모델 배포 및 서비스 운영
MLOps : The AI Lifecycle
- 자동화된 모델 빌드 및 훈련: MLOps는 모델의 개발, 훈련 및 평가를 자동화하고, 지속적으로 개선하도록 돕습니다.
- 모델 버전 관리: 훈련된 모델의 버전을 추적하고, 모델 변화를 문서화하여 협업과 모델 관리를 간편하게 합니다.
- 모델 배포 및 관리: 훈련된 모델을 실제 환경으로 배포하고, 모델의 생명주기 동안 지속적으로 모니터링하며 필요한 경우 업데이트하도록 지원합니다.
- 자동화된 테스팅 및 검증: 모델의 성능 테스트와 검증을 자동화하여 안정성을 확보하고 문제를 조기에 감지합니다.
- 지속적인 통합과 배포 (CI/CD): MLOps는 CI/CD 원칙을 적용하여 모델 업데이트를 자동화하고 배포 파이프라인을 구축합니다.
- 보안과 규정 준수: MLOps는 민감한 데이터 및 모델에 대한 보안을 강조하며 규제 요구 사항을 준수합니다.
- 협업 및 커뮤니케이션: 팀 간 협력을 촉진하고 효율적인 커뮤니케이션을 통해 프로젝트 관리를 개선합니다.
A/B 테스트
- 대안 A와 대안 B 선택: A/B 테스트는 일반적으로 현재 사용 중인 기준 대안인 "A"와 새로운 대안인 "B"를 비교합니다. "A"는 현재의 상태 또는 기존 설계를 나타내며, "B"는 변경 또는 개선된 대안을 나타냅니다.
- 랜덤 할당: 참가자 또는 사용자를 "A" 또는 "B" 그룹 중 하나에 무작위로 할당합니다. 이것은 편향을 피하고 실험의 정확성을 보장하기 위한 중요한 단계입니다.
- 목표 지표 정의: 실험의 목적에 따라 성과 지표를 정의합니다. 예를 들어, 전환율, 클릭률, 매출 등이 될 수 있습니다.
- 실험 실행: "A" 그룹과 "B" 그룹 간에 대안을 적용하고, 데이터를 수집합니다. 예를 들어, "B" 그룹에는 웹사이트 홈페이지의 새 디자인을 적용할 수 있습니다.
- 데이터 수집 및 분석: 사용자 행동에 대한 데이터를 수집하고 분석하여 두 대안 간의 성과 차이를 평가합니다. 통계적 분석을 사용하여 이 차이가 우연히 발생한 것인지 여부를 확인합니다.
- 결과 평가 및 결정: 분석 결과를 기반으로 어떤 대안이 더 우수한 결과를 나타내는지 결정하고 해당 대안을 선택합니다.
[마무리]
오늘로써 프로젝트를 위한 머신러닝 수업이 마무리되었습니다. 아직 실습을 통한 전체적인 과정을 프로젝트를 진행하듯이 정리하는 것이 남아있는데 그 부분은 짧게 끝내고 바로 머신러닝 프로젝트가 진행될 것 같습니다. 그러므로 주말에 개념적인 부분을 최대한 정리하고 머신러닝을 하는 목적에 대해서 제대로 숙지하는 시간을 가지는 것이 좋을 거 같습니다.
'AI > 머신러닝' 카테고리의 다른 글
| [AI 부트캠프] DAY 56 - 머신러닝 11 (0) | 2023.10.11 |
|---|---|
| [AI 부트캠프] DAY 54 - 머신러닝 9 (0) | 2023.10.06 |
| [AI 부트캠프] DAY 53 - 머신러닝 8 (0) | 2023.10.05 |
| [AI 부트캠프] DAY 52 - 머신러닝 7 (0) | 2023.09.28 |
| [AI 부트캠프] DAY 51 - 머신러닝 6 (0) | 2023.09.27 |




댓글