[오늘의 일지]
머신러닝 실시간 강의 - 머신러닝 정의 (Training), 데이터 분석 문제 정의 (회귀(Regression))
[상세 내용]
머신러닝 정의
Training
- 어제 마무리하지 못했던 Training부터 정리를 시작하겠습니다. 일반적으로 Training은 모델을 학습시키는 과정이라고 말할 수 있습니다. 보통 test와 training을 위해서 데이터를 분리시킨다고 한다면 training의 비율을 70~80프로를 가져가면서 학습을 시킵니다. 그런데 이렇게 어떠한 검증 없이 학습을 시키고 성능을 test 한다면 생각했던 결과를 얻지 못하는 상황을 겪을 수 있게 됩니다. 예를 들면 많은 비율의 데이터를 가지면서 학습을 통해 좋은 결과를 얻은 training에 비해서 바로 상대적으로 적은 데이터로 test를 진행한다면 안 좋은 성능이 발생할 수 있다는 것입니다. 이러한 현상을overfitting이라고 합니다. 그래서 보통은 training 데이터의 비율을 조금 낮추면서 가져가는 데이터가 있는데 validation이라고 합니다. validation은 말 그대로 trainging의 학습을 판단하기 위한 성능 검증 데이터로서 validation을 기준으로 hyper-parameter를 바꿔주면서 학습전략을 수정할 수 있는 것입니다.

Fitting&Overfitting&Underfitting
- Fitting (적합): 모델이 주어진 데이터에 대해 학습되는 과정을 나타냅니다. 이 과정은 모델이 데이터의 패턴을 파악하고 학습하여 주어진 작업을 수행하도록 하는 것을 의미합니다. 모델을 "적합"시킨다는 것은 주어진 학습 데이터에 대해 모델을 조정하고 최적화하는 과정을 나타냅니다. (P_traing↑ ⇒ P_test ↑ : fitting)
- Overfitting (과적합): 모델이 학습 데이터에 너무 맞춰져서 학습 데이터에 대한 예측 성능은 매우 좋지만, 새로운 데이터나 테스트 데이터에 대한 예측 성능이 좋지 않은 경우를 말합니다. Overfitting은 모델이 학습 데이터의 잡음(noise)까지 학습하거나 훈련 데이터의 특별한 패턴에 과도하게 민감하게 반응하는 경우에 발생할 수 있습니다. 이로 인해 모델이 새로운 데이터에 일반화하지 못하게 됩니다. (P_traing↑ ⇒ P_test ↓ : overfitting)
- Underfitting (과소적합): 모델이 학습 데이터에 대해서도 제대로 학습하지 못하고, 학습 데이터와 테스트 데이터 모두에서 성능이 좋지 않은 경우를 말합니다. Underfitting은 모델이 데이터의 복잡한 패턴이나 관계를 적절히 학습하지 못하고 너무 간단한 모델을 사용하는 경우에 발생할 수 있습니다. 이로 인해 모델이 데이터의 실제 구조를 파악하지 못하고 예측이 부정확하게 됩니다. (P_traing↓ ⇒ P_test ↓ : underfitting)

ML PJT Workflow

데이터 분석 문제 정의
회귀(Regression)
- 회귀의 직관적인 의미로서 정의한다면 주어진 데이터(X)와 원하는 값(y) 사이의 관계를 찾는 방법 혹은 주어진 데이터(X)를 통해서 원하는 값(y = target value)을 예측하는 방법이라고 할 수 있습니다.
- 관계 파악: 회귀 분석은 종속 변수와 독립 변수 간의 관계를 파악하기 위해 사용됩니다. 이것은 특정 독립 변수들이 종속 변수에 어떤 영향을 미치는지, 이 관계가 어떤 형태로 나타나는지 이해하는 데 도움이 됩니다.
- 예측: 회귀 분석을 사용하여 주어진 독립 변수 값에 대한 종속 변수의 값을 예측할 수 있습니다. 이는 예측 모델을 구축하고 새로운 데이터에 대한 예측을 수행하는 데 유용합니다.
- 설명력: 회귀 분석은 데이터의 패턴과 관계를 설명하는 데 도움이 됩니다. 특정 독립 변수들이 종속 변수에 미치는 영향을 분석하고 해석하여 인사이트를 얻을 수 있습니다.
- 모델 평가: 회귀 모델을 평가하여 모델이 데이터를 얼마나 잘 설명하고 예측하는지를 판단합니다. 이를 통해 모델의 성능을 개선하거나 다른 모델과 비교할 수 있습니다.
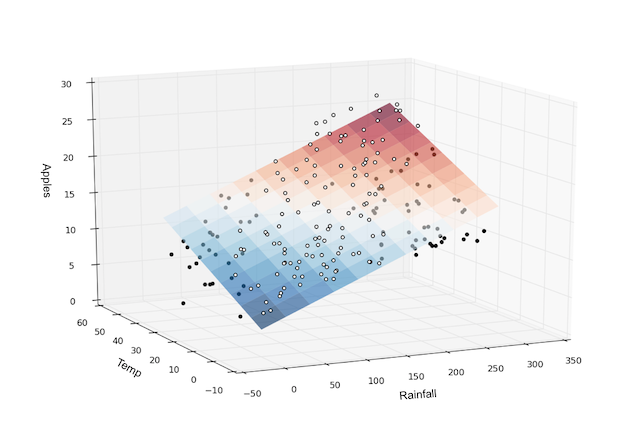
Linear Regression
Feature와 Target 사이의 관계를 선형 모델
- Feature와 Target 사이의 관계를 선형 모델(Linear Model)로 모델링하는 것은 통계 및 머신 러닝에서 흔히 사용되는 접근 방법 중 하나입니다. 선형 모델은 다음과 같이 표현될 수 있습니다.
- y는 종속 변수(Target)를 나타냅니다.
- x_1, x_2,..., x_n은 독립 변수(Features)를 나타냅니다.
- w_1, w_2, ..., w_n은 각 독립 변수의 가중치(Weights)를 나타냅니다.
- b는 절편(Intercept)을 나타냅니다.
SSE(Sam of Squared Error)와 Loss Function
SSE (Sum of Squared Errors)
- SSE는 회귀 분석에서 종종 사용되는 평가 지표 중 하나입니다.
- SSE는 각 데이터 포인트에서 모델의 예측 값과 실제 관측 값의 차이를 제곱한 값을 모두 합한 것을 나타냅니다.
- 수식으로 표현하면 다음과 같습니다.

- 여기서 n은 데이터 포인트의 수, y_i는 실제 관측값, hat{y}_i는 모델의 예측값을 나타냅니다.
- SSE를 최소화하는 것은 모델이 데이터를 가장 잘 설명하고 예측하는 것을 의미합니다. 이는 선형 회귀 모델과 같이 최소제곱법(Least Squares)을 사용하는 경우에 해당합니다.
Loss Function (손실 함수)
- Loss Function은 머신 러닝 모델에서 학습 과정에서 사용되는 함수로, 모델의 예측값과 실제 값 사이의 차이를 정량화합니다.
- 회귀 문제의 손실 함수로는 주로 MSE (Mean Squared Error)가 사용됩니다. MSE는 SSE를 데이터 포인트의 수로 나눈 값이며, 다음과 같이 표현됩니다.

- 다른 회귀 모델에서는 다른 손실 함수가 사용될 수 있으며, 손실 함수의 선택은 모델의 목적과 특성에 따라 다릅니다. 예를 들어, Huber Loss, MAE (Mean Absolute Error) 등이 사용될 수 있습니다.
- 손실 함수를 최소화하는 것은 모델의 가중치와 파라미터를 조정하여 최적의 모델을 학습하는 것을 의미합니다. 이는 경사 하강법(Gradient Descent)과 같은 최적화 알고리즘을 사용하여 수행됩니다.
요약하면, SSE는 회귀 분석에서 실제 관측값과 모델의 예측값 간의 제곱 오차를 나타내는 측정 항목이며, Loss Function은 머신 러닝 모델의 학습 과정에서 모델 성능을 평가하고 최적화하기 위해 사용되는 함수입니다.
Loss Space
- Loss Space는 머신 러닝 및 최적화 문제에서 사용되는 개념으로, 모델의 손실 함수값(Loss Function)에 따라 형성되는 공간을 나타냅니다. 이 공간은 모델의 파라미터(가중치 및 편향)에 대한 가능한 조합을 표현하며, 모델의 성능을 평가하고 최적화하는 데 사용됩니다.
- Q1. Loss가 0이 되면 어떤 의미일까요?
- A1. y_i = hat{y}_i
- Q2. Loss가 0이 되는 지점을 찾을 수 있을까요?
- A2. depends on training data
- Q3. Loss가 최소가 되는 지점을 어떻게 찾을까요?
- L'(w) = 0(analytic solution)
Loss Function Optimization
- 목표: 머신 러닝 모델을 학습시키는 과정에서 모델의 손실 함수값을 최소화하는 것이 목표입니다. 손실 함수는 모델의 예측값과 실제 관측값 간의 차이를 측정합니다.
- Gradient Descent: Gradient Descent는 현재 위치에서 손실 함수의 기울기(Gradient)를 계산하고, 기울기가 가장 큰 방향(가파른 방향)으로 파라미터를 업데이트하여 손실을 최소화하는 방향으로 이동합니다. 이 과정을 여러 번 반복하여 최적 파라미터를 찾습니다.
- 학습률 (Learning Rate): 학습률은 각 단계에서 얼마나 큰 보폭으로 이동할지 결정하는 하이퍼파라미터입니다. 적절한 학습률을 선택하는 것이 중요하며, 너무 작으면 학습이 느리게 진행되고, 너무 크면 학습이 불안정해질 수 있습니다.
- Global Minima와 Local Minima: 손실 함수 최적화는 종종 손실 함수의 모양에 따라 어려움을 겪습니다. Convex 한 손실 함수의 경우 Global Minima를 찾을 수 있지만, 비선형 손실 함수는 Local Minima와 Saddle Points에 빠질 수 있습니다.
- Local Minima 극복: Local Minima에 빠졌을 때 해결 방법 중 하나는 학습률을 조절하는 것입니다. 더 작은 학습률을 사용하면 Local Minima에서 빠져나오는 데 도움이 될 수 있습니다. 또한 초기 파라미터 설정과 초기화 방법, 다양한 최적화 알고리즘을 사용하여 최적화 과정을 개선할 수 있습니다.

Gradient Descent (GD)
- GD는 모든 훈련 데이터를 한 번에 사용하여 모델의 파라미터를 업데이트하는 최적화 알고리즘입니다.
- GD는 전체 데이터 세트를 통해 계산된 손실 함수의 그래디언트(기울기)를 사용하여 파라미터를 조정하며, 이를 통해 손실 함수를 최소화합니다.
- 한 번의 업데이트에 모든 데이터를 사용하므로 더 안정적이지만 큰 데이터셋의 경우 계산 비용이 매우 높을 수 있습니다.
Full Batch Gradient Descent (Batch GD)
- Batch GD는 모든 훈련 데이터를 한 번에 사용하여 모델의 파라미터를 업데이트하는 최적화 알고리즘입니다.
- Batch GD는 전체 데이터 세트를 통해 계산된 손실 함수의 그래디언트(기울기)를 사용하여 파라미터를 조정하며, 이를 통해 손실 함수를 최소화합니다.
- 한 번의 업데이트에 모든 데이터를 사용하므로 더 안정적이고 정확하지만 큰 데이터셋의 경우 계산 비용이 매우 높을 수 있습니다.
Mini-Batch Gradient Descent
- Mini-Batch GD는 전체 데이터를 작은 미니 배치(mini-batch)로 나누어 각 미니 배치에 대해 파라미터를 업데이트하는 최적화 알고리즘입니다.
- 미니 배치는 데이터의 일부만을 사용하므로 GD보다 계산 비용이 적게 들며, 동시에 전체 데이터의 특성을 반영할 수 있습니다.
- 일반적으로 미니 배치 크기는 2^N (예: 32, 64, 128)로 설정됩니다.
Stochastic Gradient Descent (SGD)
- SGD는 Mini-Batch GD의 특수한 경우로, 미니 배치 크기를 1로 설정한 것입니다. 즉, 각 데이터 포인트에 대해 파라미터를 업데이트합니다.
- SGD는 매우 빠른 학습 속도를 가지지만 노이즈가 많고 불안정할 수 있습니다. 하지만 이러한 노이즈는 종종 모델의 탐색을 돕고 로컬 미니마(local minima)에서 빠져나오는 데 도움이 될 수 있습니다.
- 또한, SGD는 대규모 데이터셋에서 사용할 때 매우 효과적일 수 있습니다.
Logistic Regression
- 이진 분류: 로지스틱 회귀는 주로 이진 분류 문제를 다룹니다. 이것은 두 개의 클래스 중 하나를 예측하는 문제입니다. 예를 들어, 스팸 메일 여부를 예측하거나 암 진단을 수행하는 데 사용될 수 있습니다.
- 선형 모델: 로지스틱 회귀는 선형 모델로, 입력 특성(feature)들의 가중치(weights)를 조합한 선형 결합을 사용하여 클래스를 예측합니다. 그러나 이 결과를 확률값으로 변환하기 위해 시그모이드 함수(Sigmoid Function)를 사용합니다.
- 시그모이드 함수: 로지스틱 회귀에서 선형 결합을 시그모이드 함수에 입력하면 0과 1 사이의 확률값을 출력합니다. 시그모이드 함수는 S 모양의 곡선을 가집니다.
- 파라미터 학습: 로지스틱 회귀는 최대 가능도 추정(Maximum Likelihood Estimation)을 사용하여 모델의 파라미터를 학습합니다. 학습된 파라미터는 손실 함수를 최소화하도록 조정됩니다.
- 손실 함수: 로지스틱 회귀에서는 주로 로그 손실(Log Loss) 또는 이진 크로스 엔트로피 손실(Binary Cross-Entropy Loss)을 사용하여 모델을 훈련시킵니다.

회귀 실습
- 실습의 데이터는 그 유명한 타이타닉 데이터를 사용하였고 작업환경은 구글의 colab에서 진행되었습니다.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
submission = pd.read_csv('/content/drive/MyDrive/Colab Notebooks/data/titanic/gender_submission.csv')
test = pd.read_csv('/content/drive/MyDrive/Colab Notebooks/data/titanic/test.csv')
train = pd.read_csv('/content/drive/MyDrive/Colab Notebooks/data/titanic/train.csv')
# 1. 결측치 체크
train[train.isnull().any(axis=1)]
# 2. dtype이 object인 column 찾기
train.loc[:, train.dtypes == 'object'] # dataframe
train.columns[train.dtypes == 'object'] # columns
# 3. target value distribution 체크
sns.countplot(data=train, x='Survived')
train.Survived.value_counts()
# feature engineering
# 1. Cabin column의 결측치 여부가 Survived에 영향이 있는가?
train.loc[train.Cabin.isnull(), 'Survived'].mean(), train.loc[train.Cabin.notnull(), 'Survived'].mean()
# 2. 영향이 있는것 같으니, Cabin값이 있으면 1, 없으면 0 값을 가지는 is_Cabin이라는 column을 만들어봅시다.
train['is_Cabin'] = train.Cabin.notnull() * 1
# 3. SibSp + Parch = FamilySize(비슷해보이는 피처 합치기)
train['FamilySize'] = train['SibSp'] + train['Parch']
# 4. drop columns(수치적으로 필요없을 거 같은 object탑이 피처 포함 제거)
train = train.drop(columns=['PassengerId', 'Name', 'SibSp', 'Parch', 'Cabin', 'Ticket'])
# 5. Age column
train.Age = train.Age.fillna(train.Age.median())
#train.Age.mean(), train.Age.min(), train.Age.max(), train.Age.median(), train.Age.mode()
# 6. dropna(정말 소수의 데이터는 과감하게 버리는 것도 나쁘지 않다.)
train = train.dropna()
train.info()
# 7. Encoding categorical feature
# 1) Ordinal encoding
#train.Sex = pd.factorize(train.Sex, sort=True)[0]
#train.loc[:, "Sex"] = pd.factorize(train.Sex, sort=True)[0]
_map = {'male': 1, 'female': 2}
train.Sex = train.Sex.map(_map)
# 2) One-hot encoding
train = pd.get_dummies(data=train, columns=['Embarked'])
# data setting for training
from sklearn.model_selection import train_test_split
X = train.drop(columns=["Survived"]) # feature vector
y = train.Survived # target value
# 일반적인 데이터 설정(외워두면 좋을정도로 많이 쓰는 기본적인 형태)
X_train, X_val, y_train, y_val = train_test_split(X, y, test_size=0.2, random_state=42)
print(X_train.shape, X_val.shape, y_train.shape, y_val.shape)
# training(= fitting)
# sklearn에서 학습을 하는 방법
# 1. 사용할 함수를 불러온다.
# 2. 해당 함수를 선언한다.
# 3. fit()
from sklearn.linear_model import LinearRegression, LogisticRegression
reg = LinearRegression()
reg.fit(x_train,y_train)
lreg = LogisticRegression()
lreg.fit(x_train,y_train)
from sklearn.metrics import mean_squared_error
from sklearn.metrics import mean_squared_error
from sklearn.metrics import accuracy_score
print("Linear Regression MSE : %.4f" % mean_squared_error(y_train, reg.predict(x_train)))
print("Logistic Regression MSE : %.4f" % mean_squared_error(y_train, lreg.predict_proba(x_train)[:, 1]))
print("Train ACC : %.4f" % accuracy_score(y_train, lreg.predict(x_train)))
print("Validation : %.4f"% accuracy_score(y_val, lreg.predict(x_val)))
>>>
Linear Regression MSE : 0.1414
Logistic Regression MSE : 0.1390
Train ACC : 0.7975
Validation : 0.7978
[마무리]
오늘은 본격적으로 모델 학습에 대한 수업과 실습까지 대략 총 8시간의 강의를 들었습니다. 실시간 강의가 좋은 점은 실시간으로 수업을 듣다 보니 내 의지와 상관없이 시간을 알차게 사용할 수 있어서 좋은 거 같습니다. 또 피드백도 바로바로 받을 수 있다는 점도 확실히 좋은 부분이라고 생각합니다. 아무튼 강의가 실습까지 이어진 것은 좋았는데 아직 익숙하지 못한 부분이다 보니 추석 연휴에 복습을 적당히 해줘야 할거 같습니다.
'AI > 머신러닝' 카테고리의 다른 글
| [AI 부트캠프] DAY 53 - 머신러닝 8 (0) | 2023.10.05 |
|---|---|
| [AI 부트캠프] DAY 52 - 머신러닝 7 (0) | 2023.09.28 |
| [AI 부트캠프] DAY 50 - 머신러닝 5 (0) | 2023.09.26 |
| [AI 부트캠프] DAY 49 - 머신러닝 4 (0) | 2023.09.23 |
| [AI 부트캠프] DAY 48 - 머신러닝 3 (0) | 2023.09.22 |




댓글