[오늘의 일지]
머신러닝 실시간 강의 - 데이터 분석 문제 정의 (클러스터링(Clustering), Boosting)
[상세 내용]
데이터 분석 문제 정의
클러스터링(Clustering)
정의
- 클러스터링은 비슷한 데이터를 같은 그룹에 묶고, 비슷하지 않은 데이터를 다른 그룹으로 분리하여 결국 데이터를 서로 비슷한 특성을 가진 그룹끼리 모이게 하는 데이터 분석 기술입니다.
K-Means Clustering
- K-Means Clustering은 가장 직관적이고 이해하기 쉬운 클러스터링 방법으로 'K-평균 알고리즘'으로 불리며, 데이터를 평균(mean)을 기준으로 묶어주는 방법으로 알려져 있습니다. 이 알고리즘은 엄청나게 빠른 속도로 수행되며, 결과가 반드시 나오는 것이 보장되어 있어 데이터 클러스터링의 대표적인 방법 중 하나입니다.
K-Means Clustering의 원리
- 랜덤 하게 K개의 데이터를 선택하여 기준으로 정한다.
- 선택하지 않은 모든 데이터에 대해서 선택한 K개의 데이터 중 가장 가까운 데이터를 찾는다.
- 가깝다고 정해진 데이터끼리 묶어서 새로운 클러스터를 만든다.
- 새롭게 구성된 클러스터에 속하는 데이터들의 평균을 구한다.
- 새로 계산한 평균을 새로운 K개의 기준으로 정한다.
- 2번 과정부터 다시 반복한다.
- 새롭게 업데이트되는 데이터가 없다면 종료한다.
K-Means Clustering 과정


K-means의 한계점
- 초기에 선택되는 K개의 데이터(initial centroid)에 따라 성능 편차가 크다. (보완: K-means++)
- 평균이 의미가 없는 데이터(categorical feature)에선 효과가 없다. (보완: K-modes, K-prototpye)
- outlier(이상치)에 민감하여 결과가 치우쳐서 나올 수 있다. (보완: K-mediods(CLALANS))
- 데이터의 분포가 구형(hyper-spherical)이 아니면, 클러스터 생성이 힘들다. (보완: HAC, DBSCAN)
Hierarchical Agglomerative Clustering (HAC)
- K-평균 클러스터링과 함께 가장 많이 사용되는 클러스터링 방법 중 하나는 "계층적 클러스터링"입니다. 이 방법은 가장 비슷한 데이터끼리 시작하여 점진적으로 모든 클러스터들을 묶어나가는 방식으로 수행됩니다. 이러한 방식은 작은 클러스터부터 시작하여 점차적으로 큰 클러스터를 형성하는 "상향식" 계층적 클러스터링 방법으로 알려져 있으며, 데이터의 계층 구조를 파악하기에 매우 유용합니다.
HAC의 원리
- 모든 데이터를 각자 하나의 클러스터로 세팅한다.
- 모든 데이터 중에 가장 가까운 두 개의 데이터를 묶는다.
- 그다음 가까운 데이터를 묶는다. 만약에 이미 묶여있는 클러스터와 데이터가 묶이는 경우라면, 하나의 클러스터로 합친다.
- 계속해서 상향식으로 클러스터를 합쳐가다가, 제시한 클러스터 개수가 되면 멈춘다.

HAC의 과정
- metric(거리함수)과 linkage(연결 방식)에 따라 전혀 다른 방식으로 작동한다.
- 데이터 사이의 모든 거리를 계산해야 해서 최소의 계산이 필요하다.
- 데이터 간의 연결성을 판단하기 때문에, linkage와 metric에 따라 여러 형태의 데이터 분포를 가지는 데이터를 클러스터링 할 수 있다.
linkage : single, average, complete, ward 정리
- single : 각 클러스터 내의 모든 데이터 포인트 쌍 간의 거리 중 가장 가까운 거리를 사용합니다. 이 방법은 두 클러스터 중 가장 가까운 데이터 포인트 쌍의 거리를 고려하므로 클러스터 간에 뾰족한 형태의 클러스터를 형성할 수 있습니다.
Average linkage : 두 클러스터 사이의 거리를 계산할 때, 각 클러스터 내의 모든 데이터 포인트 쌍 간의 거리의 평균이 가장 가까운 클러스터를 연결합니다. 이 방법은 각 클러스터의 모든 데이터 포인트 간의 거리를 고려하므로 더 균형 잡힌 클러스터를 형성할 수 있습니다.
Complete linkage : 두 클러스터 사이의 거리를 계산할 때, 각 클러스터 내의 모든 데이터 포인트 쌍 간의 거리 중 가장 멀리 떨어진 거리를 사용합니다. 이 방법은 클러스터 간에 멀리 떨어진 데이터 포인트 쌍의 거리를 고려하므로 클러스터 간의 거리가 큰 클러스터를 형성할 수 있습니다.
Ward linkage : 클러스터 간의 거리를 계산할 때, 두 클러스터를 합쳤을 때 inertia가 가장 작아지는 클러스터를 연결합니다. 이 방법은 클러스터 간의 분산을 최소화하려고 하므로 비교적 균일한 크기의 클러스터를 형성하려는 경향이 있습니다.
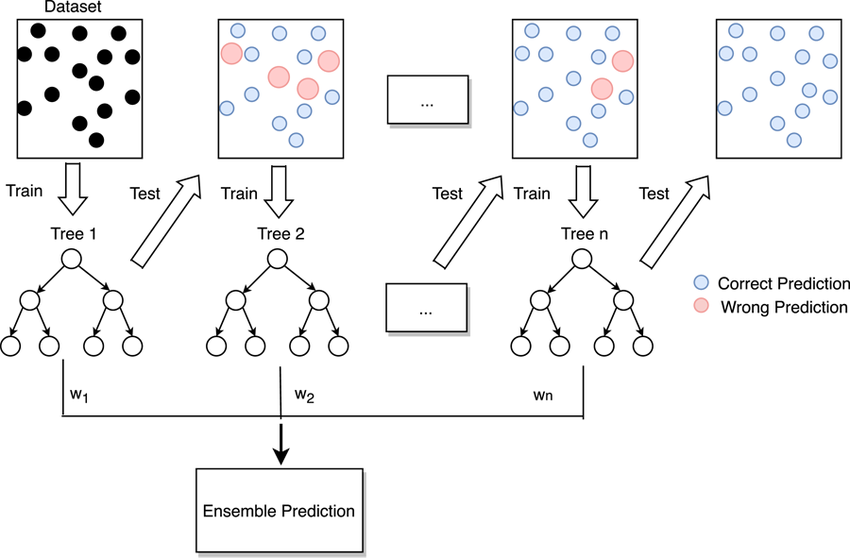
Boosting (Ada Boost)
- 이전 트리를 보완하는 방식으로 학습되는 앙상블 기법

Gradient Boosting Machine
- Boosting + Gradient Descent Algorithm + Regularization
XGBoost (XGB)
- GBDT with System Optimization
- kaggle 같은 실전 데이터 분석 대회에서 가장 많이 사용하는 모델
- GBDT가 학습이 오래 걸린다는 단점을 하드웨어 최적화를 통해서 해결합니다.
- GBDT를 대중화시킨 첫 번째 모델
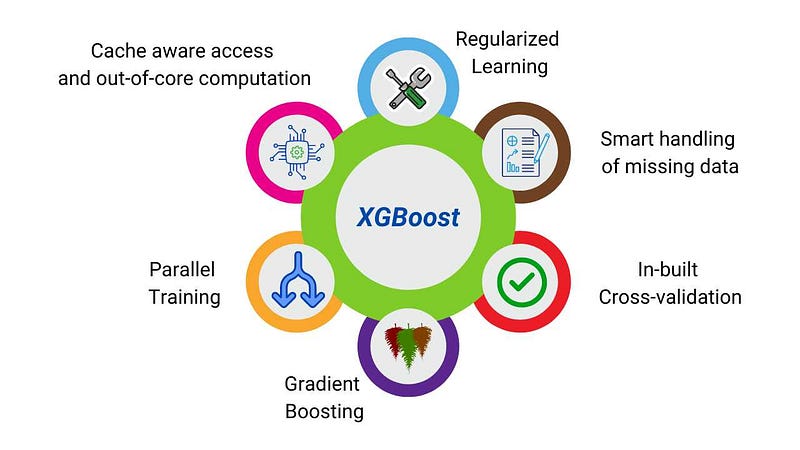
Gradient Boosting algorithm with System Optimization
System Optimization
- Parallelization (병렬화)
- Tree Pruning (트리 가지치기)
- Hardware Optimization (하드웨어 최적화)
Algorithm Enhancement
- Regularization (정규화)
- Sparsity Awareness (희소성 인식)
- Weighted Quantile Sketch (가중치 분위수 스케치)
Hyper-parameter Tuning (feat. Scikit-Learn API, 1000 ≤ N ≤ 30000)
CART 관련 param
max_depth : 5~15
max_bin :
subsample :
colsample_bytree : global randomization
colsample_bylevel :
colsample_bynode : local randomization (0.5~0.8)
reg_alpha :
reg_lambda : regularization parameter (0.5~5.0)
scale_pos_weight :
Tree ensemble 관련 param
n_estimators : 50~2000
learning_rate : pseudo-residual parameter(0.3~0.01)
objective :
booster :
n_jobs :
tree_method : best split을 찾을 때 데이터를 사용하는 방법('exact'/'approximate'/'gpu_hist')
random_state :
early_stopping_rounds : + eval_metric validation_data
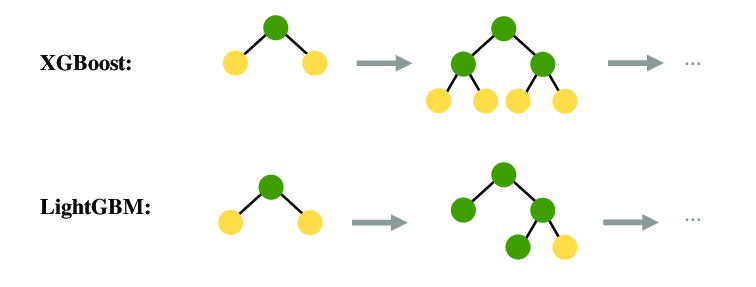
LightGBM (LGBM)
- XGBoost보다 가볍고 빠른 GBDT 모델
- kaggle 같은 실전 데이터 분석 대회에서 가장 많이 사용하는 모델
- split point를 찾는 방식에서 효율을 극대화하여, 훨씬 작은 메모리로 빠르게 성능이 좋은 트리를 만듭니다.
- n_rows가 10000 이하라면, overfitting이 되기 쉽다는 단점이 있습니다.
Hyper-parameter Tuning (feat. Scikit-Learn API, 30000 ≤ N)
CART 관련 param
max_depth : 15~25
num_leaves : max (#leaf nodes) ≤ 2(max_depth)
min_child_samples : min_samples_leaf (1~100)
subsample_for_bin :
colsample_bytree : node split시 동일한 세팅이어야 하기에 global randomization을 제공 (0.5~0.8)
reg_alpha :
reg_lambda :
class_weight :
Tree ensemble 관련 param
n_estimators : 50~
learning_rate : 0.3~0.001
objective :
boosting_type :
n_jobs :
slient : -1 (=verbose)
random_state :
[마무리]
오늘은 일주일 간의 긴 연휴를 끝내고 지난주 수업에서 이어진 부분부터 다시 수업이 진행되었습니다. 사실 쉬는 기간 동안 공부를 전혀 하지 않았기 때문에 다시 적응하는데 조금 힘든 점도 있었지만 최대한 집중해 보려고 노력했습니다. 오늘 수업 내용은 실습을 위한 머신러닝 라이브러리에 대한 개념을 배우는 과정이었기 때문에 나중에 실습을 통해서 좀 더 익숙해지도록 노력해 봐야 될 거 같습니다.
'AI > 머신러닝' 카테고리의 다른 글
| [AI 부트캠프] DAY 55 - 머신러닝 10 (0) | 2023.10.07 |
|---|---|
| [AI 부트캠프] DAY 54 - 머신러닝 9 (0) | 2023.10.06 |
| [AI 부트캠프] DAY 52 - 머신러닝 7 (0) | 2023.09.28 |
| [AI 부트캠프] DAY 51 - 머신러닝 6 (0) | 2023.09.27 |
| [AI 부트캠프] DAY 50 - 머신러닝 5 (0) | 2023.09.26 |




댓글