[오늘의 일지]
머신러닝 녹화 강의 - 머신러닝을 위한 개념 수업 (eXplainable Method, Clustering)
[상세 내용]
머신러닝을 위한 개념
eXplainable Method
- "eXplainable Method"은 보통 "XAI" 또는 "Explainable Artificial Intelligence"의 줄임말로 사용되며, 인공 지능 모델이나 시스템의 작동 방식을 해석하고 설명하는 데 사용되는 방법을 가리킵니다. 이것은 주로 머신 러닝 모델 및 딥 러닝 네트워크와 같은 복잡한 AI 시스템에서 중요한 개념입니다. XAI 기술은 블랙박스로 알려진 머신 러닝 모델의 한계를 극복하려는 노력의 일환으로 발전하고 있으며, 이는 의료 진단, 금융 예측, 자율 주행 자동차, 법률 등 다양한 응용 분야에서 중요한 역할을 하고 있습니다.
Model Black Box
- "Model Black Box"란 일반적으로 모델의 내부 작동 방식이나 의사 결정 과정이 외부에 의해 알려지지 않고 완전히 불투명한 상태를 가리킵니다. 이 용어는 주로 머신 러닝 및 딥 러닝 모델에 대해 사용되며, 모델이 어떻게 입력 데이터를 처리하고 출력을 생성하는지에 대한 이해가 부족한 경우를 설명하는 데 사용됩니다.
Explainability vs Performance

- Model Complexity 가 높은 (해석력이 낮은) Model에 대해 해석을 얻으려는 연구가 많이 이루어짐

Grad-CAM
- Grad-CAM은 "Gradient-weighted Class Activation Mapping"의 약어로, 딥 러닝 모델에서 특정 클래스를 강조하는 데 사용되는 시각화 기술입니다. 주로 이미지 분류 모델에서 해당 클래스에 대한 중요한 위치를 시각적으로 확인하는 데 사용됩니다. Grad-CAM은 모델의 결과를 해석하고 모델이 어떤 부분을 기반으로 판단을 내릴지를 설명하는 데 도움을 줍니다.
- Gradient (기울기): 뉴럴 네트워크에서는 역전파 알고리즘을 사용하여 손실 함수에 대한 기울기(gradient)를 계산합니다. 이 기울기는 각 뉴런의 활성화에 대한 손실 함수의 민감도를 나타냅니다.
- Class Activation Map (CAM): CAM은 이미지 분류 모델에서 어떤 부분이 특정 클래스에 대한 예측을 만들 때 중요한지를 시각적으로 표시하는 방법입니다. CAM은 모델의 마지막 합성곱 층의 출력과 클래스와 관련된 가중치를 사용하여 계산됩니다.
- Grad-CAM을 사용하면 모델의 예측을 이해하기 위해 어떤 부분이 결정적으로 작용하는지를 시각적으로 확인할 수 있으므로, 모델의 해석성을 향상시키고 모델을 디버깅하거나 개선하는 데 도움이 됩니다. Grad-CAM은 주로 컴퓨터 비전 작업에서 사용되며, 객체 감지, 이미지 분류, 시맨틱 분할 등 다양한 작업에 적용됩니다.
Interpretable Machine Learning (Explainability이 높은 모델)
- Interpretable Machine Learning은 머신 러닝 모델의 예측 및 결정 과정을 이해하고 설명할 수 있는 능력을 갖춘 기계 학습의 분야를 가리킵니다. 이는 모델이 어떻게 작동하며, 왜 특정 예측을 내리는지를 비전문가에게 명확하게 전달하려는 노력을 나타냅니다.
Interpretability
- Interpretability)은 기계 학습 및 인공 지능 모델이 내부 작동 방식과 결정 과정을 이해하고 설명할 수 있는 정도를 나타내는 개념입니다. 해석가능성은 모델이 어떻게 작동하는지를 비전문가에게 투명하게 전달하고, 모델의 예측이나 결정에 대한 이유를 설명할 수 있는 능력을 가리킵니다.
interpretable models
- interpretable models은 기계 학습 또는 통계 모델로, 그들이 예측이나 의사 결정을 어떻게 내리는지를 명확하게 이해할 수 있도록 설계되고 구성된 모델입니다. 이러한 모델은 의사 결정 과정에 투명성과 통찰력을 가질 때 중요한 경우에 선호됩니다. 이는 특히 의료, 금융, 법률 등 다양한 분야에서 가치 있습니다.
- interpretable models은 투명성, 책임성 및 규제 준수가 중요한 응용 분야에서 특히 중요합니다. 이러한 모델은 모델이 특정한 결정을 내린 이유를 이해하고, 편견을 감지하고 개선하며, 윤리적 및 법적 표준과 일치시키기 위해 사용될 수 있습니다.
- 모델의 예시는 다음과 같습니다. Linear Regression, Logistic Regression, Generalized Linear Models, Generalized Additive Models - Decision Tree, Naïve Bayes Classifier, K-Nearest Neighbors
Explainability이 낯은 모델의 해석력을 높이기 위한 노력
Global VS Local 비교
Global (전역):
- 전반적인 관점: 전역적인 관점에서는 데이터 집합이나 시스템 전체에 대한 특성을 나타냅니다.
- 전체 데이터에 대한 통계: 데이터의 전체적인 통계를 계산하거나 모델의 전체 성능을 평가하는 데 사용됩니다.
- 일반적인 특성: 전역적인 특성은 주로 모든 데이터 포인트 또는 모델에 대한 통계를 요약하는 데 사용됩니다.
- 예시: 전체 고객 기반의 평균 구매액, 모델의 정확도, 분류 모델의 ROC 곡선 등이 전역적인 관점에서의 측정 예시입니다.
Local (지역):
- 개별 관점: 지역적인 관점에서는 데이터의 개별 포인트나 모델의 특정 예측에 초점을 맞춥니다.
- 개별 데이터 포인트에 대한 특성: 데이터 포인트의 개별적인 특성을 이해하거나 개별 예측 결과를 분석하는 데 사용됩니다.
- 특이한 상황: 지역적인 특성은 일반적이지 않은 상황이나 이상치와 같은 특이한 상황을 식별하는 데 사용됩니다.
- 예시: 특정 고객의 구매 이력, 모델이 특정 이미지를 분류한 이유, 개별 데이터 포인트의 이상치 여부 등이 지역적인 관점에서의 측정 예시입니다.
간단히 말해, "Global"은 전체를 대표하고 일반적인 특성을 나타내며, "Local"은 개별적이며 특이한 상황을 다루는 데 사용됩니다. 이 두 개념은 데이터 분석, 모델 해석, 예측 해석 등 다양한 분야에서 중요한 역할을 합니다. 예를 들어, 모델의 전체적인 성능을 평가하는 데 "Global" 메트릭스를 사용하고, 모델의 개별 예측 결과를 해석하거나 오류를 디버깅하는 데 "Local" 해석을 적용할 수 있습니다.
Local Model-Agnostic Methods
- 위에서 로컬에 대해서 설명한 이유는 해석력을 높이기 위한 모델인 LIME과 SHAP의 배경을 이해하기 위함이었습니다. 이제 LIME과 SHAP에 대해 자세하게 알아보겠습니다.
LIME
- LIME은 Local Interpretable Model-Agnostic Explanations의 약어로서 풀이하자면 다음과 같습니다.
- Local : 특정 변수
- Interpretable : 해석 가능한
- Model-agnostic : Model Free (어떠한 Model이라도 적용 가능)
- Explanation : 설명할 수 있음
- etc : 숫자, 텍스트, 이미지 등 모든 데이터에 적용 가능
LIME의 원리
단계 1: 모델링
- 다양한 모델 유형 (가중치 기반 모델, 트리 기반 모델, 심층 학습 모델 등)을 사용하여 학습을 수행합니다.
- 모델의 해석 가능성을 유지하면서 학습합니다.
- LIME은 모델의 확장성을 보장합니다.
단계 2: 데이터셋 및 예측
- 학습이 완료된 모델을 사용하여 학습 데이터 또는 검증 데이터에 대한 예측을 수행합니다.
단계 3: 데이터 추출
- 타깃 데이터를 추출합니다.
- 예를 들어, 학습 및 검증 데이터에서 초 고효율 군과 같이 관심 있는 데이터를 추출합니다.
- 높은 성능을 보이는 데이터를 식별하기 위해 MSE(평균 제곱 오차) 등과 같은 지표를 사용하여 데이터를 추출합니다.
단계 4: 설명
- 추출한 데이터에 대한 중요한 요소(특성)를 도출합니다.
- LIME을 사용하여 중요한 요소를 도출합니다.
단계 5: 결정
- 도출된 중요한 요소를 기반으로 데이터의 실제 중요성을 평가합니다.
- 중요한 요소와 목표 변수(Y) 간의 상관관계 및 시각화를 통해 통찰력을 얻습니다.
- 이 정보를 기반으로 결정을 내립니다.
SHAP
- SHAP(Shapley Additive Explanations)는 기계 학습 모델의 예측을 해석하고 설명하기 위한 통계적 기술 및 프레임워크입니다. SHAP은 예측 값을 어떤 특성 또는 요소에 얼마나 기여하는지를 평가하는 데 사용되며, 이를 통해 모델의 예측을 해석하는 데 도움을 줍니다. SHAP은 Shapley 값이라는 게임 이론의 개념에서 영감을 받아 개발되었습니다.
- Shapley 값: SHAP은 Shapley 값이라는 개념을 모델 해석에 적용합니다. Shapley 값은 다양한 특성 또는 요소가 협력하여 어떤 결과를 만들었을 때 각 특성 또는 요소의 공헌도를 평가하는 방법입니다. SHAP은 이러한 공헌도를 모델의 예측에 적용하여 각 특성의 중요성을 결정합니다.
- 모델에 대한 모델 독립적: SHAP은 모델에 독립적으로 적용할 수 있습니다. 즉, 어떤 종류의 기계 학습 모델에도 적용 가능하며, 특정 모델 아키텍처에 종속적이지 않습니다.
- 간결하고 해석 가능한 결과 제공: SHAP은 각 특성 또는 요소가 예측에 어떻게 기여하는지를 설명 가능한 방식으로 제공합니다. 이로써 사용자는 모델의 예측을 이해하고 중요한 특성을 식별할 수 있습니다.
- 공평성 및 편향 검출: SHAP을 사용하면 모델이 어떤 특성에 대해 편향적인 결정을 내릴 가능성을 감지하고 해결하는 데 도움이 됩니다. 이를 통해 모델의 공정성을 확인하고 개선할 수 있습니다.
SHAP의 원리
SHAP Summary Plot
- SHAP Summary Plot은 모든 특성에 대한 SHAP 값의 분포를 보여줍니다.
- 특성의 중요성은 절댓값이 큰 SHAP 값에 해당하는 특성일수록 높다고 볼 수 있습니다.
- SHAP Summary Plot을 통해 모델 전체의 특성 중요성을 파악할 수 있습니다.
Force Plot
- Force Plot은 개별 예측에 대한 SHAP 값을 시각화하는 도구입니다.
- Force Plot을 통해 특정 예측의 SHAP 값을 해석하고, 각 특성이 해당 예측에 어떻게 영향을 미치는지를 이해할 수 있습니다.
- 각 특성의 SHAP 값은 해당 예측에서의 기여도를 나타냅니다. 양수 값은 예측을 증가시키는 방향으로 기여하고, 음수 값은 예측을 감소시키는 방향으로 기여합니다.
Waterfall Plot
- Waterfall Plot은 Force Plot과 유사하게 개별 예측에 대한 SHAP 값을 시각화합니다.
- 각 특성의 SHAP 값이 어떻게 누적되어 최종 예측 값으로 이어지는지를 보여줍니다.
- Waterfall Plot을 통해 SHAP 값의 누적 효과를 시각적으로 이해할 수 있습니다.
Independency Plot
- Independency Plot은 특정 특성의 SHAP 값과 해당 특성의 값 사이의 관계를 시각화합니다.
- 특정 특성이 예측에 미치는 영향이 해당 특성의 값에 따라 어떻게 변하는지를 이해할 수 있습니다.
SHAP Summary Plot
- 다른 예측 또는 클래스 간에 SHAP Summary Plot을 비교하여 특정 예측이나 클래스와 다른 예측 또는 클래스 간의 특성 중요성 차이를 이해할 수 있습니다.
Clustering
- 클러스터링(Clustering)은 데이터 마이닝과 머신 러닝 분야에서 사용되는 중요한 개념으로, 유사한 특성을 가진 데이터 포인트들을 그룹화하는 기술이나 작업을 가리킵니다. 클러스터링은 데이터의 패턴을 식별하고 데이터를 의미 있는 부분 집합으로 분할하는 데 사용됩니다. 이를 통해 데이터를 더 잘 이해하고 분석할 수 있으며, 비슷한 특성을 가진 데이터 포인트 간의 관계를 파악할 수 있습니다.
Distance
- 클러스터링에 관련된 알고리즘을 설명하기 위해서는 몇 가지 중요한 거리에 대해서 이해를 하고 넘어가야 합니다. 지난 EDA 수업의 마지막쯤에 선형 대수학의 기초를 배울 때 몇 가지 배워서 일지에 정리해 둔 것이 있지만 복습한다고 치고 다시 정리해 보도록 하겠습니다.
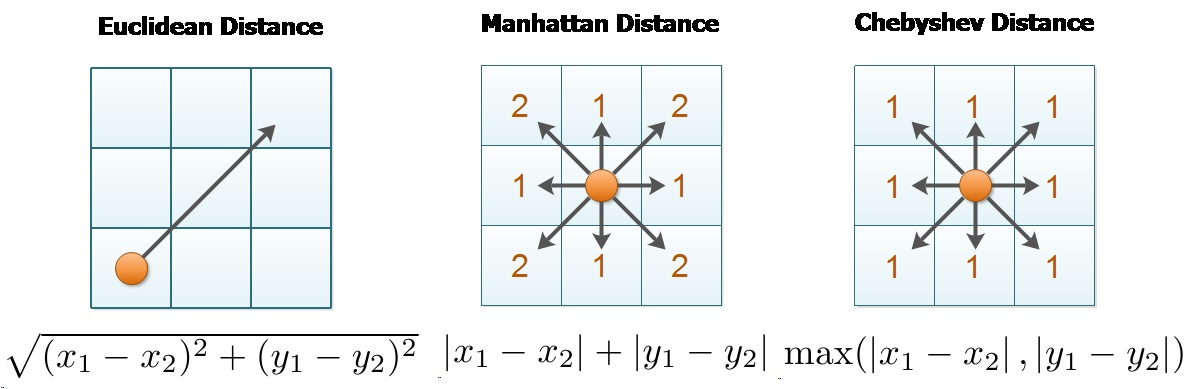
Euclidian Distance (유클리디안 거리)
- 유클리디안 거리(Euclidean distance)는 공간 상의 두 점 사이의 거리를 측정하는 데 사용되는 가장 기본적이고 널리 사용되는 거리 측정 방법 중 하나입니다. 이 거리 측정 방법은 피타고라스의 정리와 관련이 있으며, 공간에서 두 점 사이의 직선거리를 계산합니다. 유클리디안 거리는 주로 다차원 공간에서 사용되며, 두 점 간의 차원별 거리의 제곱을 합산한 후 제곱근을 취한 값으로 표현됩니다.

Manhattan Distance (맨하탄 거리)
- 맨해튼 거리(Manhattan distance), 또는 L1 거리는 두 점 사이의 거리를 측정하는 데 사용되는 거리 측정 방법 중 하나입니다. 이 거리 측정 방법은 두 점 간의 직선거리가 아니라 격자 형태의 그리드를 따라 이동하는 데 필요한 "거리"를 측정합니다. 맨해튼 거리는 이름에서 알 수 있듯이, 도시의 구획을 가로지르는 데 필요한 이동 거리와 유사합니다. 맨해튼 거리는 주로 다른 두 지점 간의 최단 경로를 계산하거나 위치 기반 검색 및 머신 러닝에서 사용됩니다.

Cosine Distance (코사인 거리)
- 코사인 거리(Cosine Distance)는 벡터 공간에서 두 벡터 간의 유사성을 측정하는 데 사용되는 거리 측정 방법 중 하나입니다. 코사인 거리는 두 벡터 사이의 각도를 이용하여 계산되며, 각도가 작을수록 두 벡터가 더 유사하다고 간주됩니다. 주로 텍스트 데이터 마이닝, 정보 검색, 문서 유사성 측정, 추천 시스템 등에서 벡터 간의 유사성을 계산하는 데 활용됩니다.

Minkowski Distance (민코프스키 거리)
- 민코프스키 거리(Minkowski Distance)는 m차원 민코프스키 공간에서의 거리를 나타내며, m 값에 따라 다양한 거리 측정 방법을 표현합니다. m=1인 경우 맨하탄 거리와 동일하며, m=2인 경우 유클리디안 거리와 동일합니다. 이 거리 측정 방법은 정수 값이 아니어도 되지만 반드시 1보다 커야 하며, 맨하탄과 유클리디안 거리를 일반화한 형태로 사용됩니다.
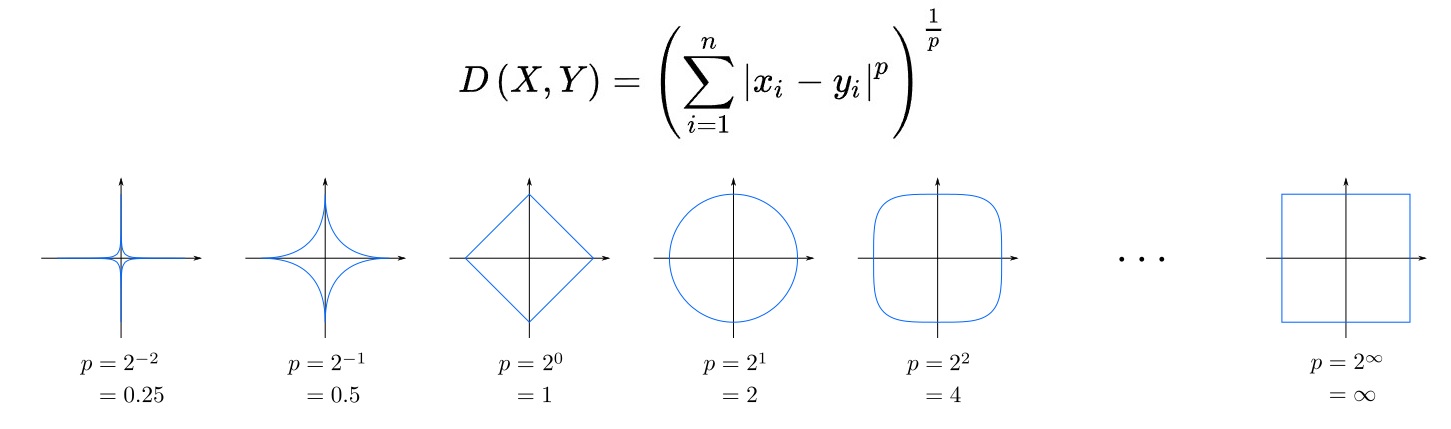
Chebychev Distance (체비셰프 거리)
- 주어진 점으로부터 인접한 8개의 셀들을 동일한 거리로 측정하는 것은 "체비셰프 거리(Chebyshev Distance)"입니다. 이 거리 측정 방법은 맨하탄 거리와는 달리 모든 방향(수평, 수직, 대각선)으로의 이동을 동일한 거리로 처리합니다. 반면, 맨하탄 거리는 주로 인접한 4개의 셀을 동일한 거리로 처리합니다.
Levenshtein Distance (리벤슈테인 거리)
- 레벤슈타인 거리(Levenshtein Distance), 편집 거리(Edit Distance), 또는 문자열 거리는 두 문자열 사이의 유사성을 측정하는 데 사용되는 거리 측정 방법 중 하나입니다. 이 거리는 한 문자열을 다른 문자열로 변환하기 위해 필요한 최소 편집 연산(삽입, 삭제, 대체)의 횟수를 나타냅니다. 레벤슈타인 거리는 문자열 비교, 철자 교정, 자연어 처리, 데이터 정제 등 다양한 응용 분야에서 활용됩니다.

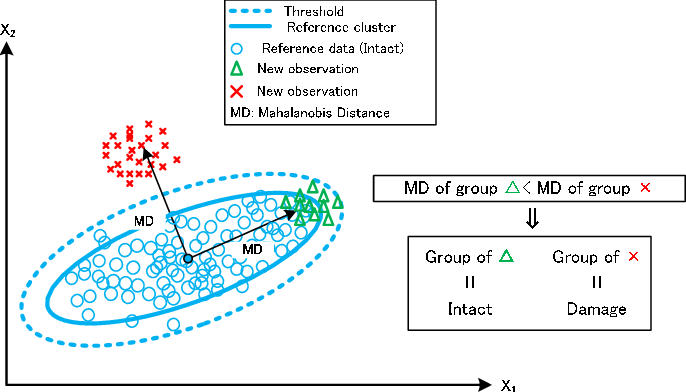
Mahalanobis Distance (마할라노비스 거리)
- 마할라노비스 거리(Mahalanobis Distance)는 다차원 공간에서 두 점 사이의 거리를 측정하는 데 사용되는 거리 측정 방법 중 하나입니다. 마할라노비스 거리는 유클리디안 거리를 일반화한 형태로, 데이터의 공분산 구조를 고려하여 거리를 계산합니다. 이 거리 측정 방법은 다차원 공간에서 데이터 포인트 간의 상관관계와 분포를 고려하므로 이상치(outliers)를 감지하거나 클러스터링, 분류, 판별 분석 등의 다양한 머신 러닝 및 통계 분석 작업에 유용합니다.
Clustering 알고리즘
K-means
- K-평균 클러스터링(K-means clustering)은 비지도 학습(Unsupervised Learning) 알고리즘 중 하나로, 주어진 데이터를 K개의 클러스터로 그룹화하는 작업을 수행합니다. 각 클러스터는 유사한 데이터 포인트들의 집합으로 구성되며, K는 사용자가 지정하는 하이퍼파라미터로 클러스터의 개수를 나타냅니다. K-평균 클러스터링의 목표는 각 데이터 포인트를 가장 가까운 클러스터의 중심(centroid)에 할당하고, 이를 통해 클러스터를 형성하는 것입니다.
K-means의 원리
- 초기 중심 선택: 먼저 K개의 초기 중심을 선택합니다. 이러한 초기 중심은 데이터 포인트 중에서 무작위로 선택하거나 다른 방법을 통해 초기화할 수 있습니다.
- 할당 단계: 각 데이터 포인트를 가장 가까운 중심에 할당합니다. 일반적으로는 유클리디안 거리 또는 다른 거리 측정 방법을 사용하여 가장 가까운 중심을 찾습니다.
- 업데이트 단계: 각 클러스터의 중심을 해당 클러스터에 속한 모든 데이터 포인트의 평균(또는 중간값)으로 업데이트합니다.
- 수렴 확인: 클러스터 할당과 중심 업데이트를 반복하면서 알고리즘이 수렴할 때까지 진행합니다. 일반적으로는 할당과 업데이트 사이의 거리의 변화가 미미할 때 알고리즘이 수렴했다고 판단합니다.
- 결과 출력: 알고리즘이 수렴하면 각 데이터 포인트는 하나의 클러스터에 속하고, 클러스터의 중심은 해당 클러스터의 대푯값이 됩니다.
Hierarchical Clustering
- 계층적 클러스터링(Hierarchical Clustering)은 데이터를 계층적 구조로 클러스터링 하는 비지도 학습 알고리즘 중 하나입니다. 이 알고리즘은 데이터 포인트 간의 유사성을 기반으로 계층적인 클러스터 트리를 구성합니다. 계층적 클러스터링은 클러스터를 하위 클러스터로 분할하거나 상위 클러스터로 병합하는 데 사용되며, 이러한 계층 구조를 시각화하면 데이터의 유사성과 관계를 이해하는 데 도움이 됩니다.
Hierarchical Clustering의 원리
- 초기화: 각 데이터 포인트를 개별 클러스터로 시작합니다. 따라서 데이터 포인트의 수만큼 초기 클러스터가 형성됩니다.
- 클러스터 간 거리 측정: 각 클러스터 간의 거리 또는 유사성을 측정합니다. 이를 위해 다양한 거리 측정 방법(예: 유클리디안 거리, 맨하탄 거리, 코사인 유사도 등)을 사용할 수 있습니다.
- 가장 유사한 클러스터 병합 또는 분할: 가장 가까운 두 클러스터를 병합하거나 모든 클러스터를 분할합니다. 이 단계에서 클러스터 간의 거리를 기준으로 결정됩니다.
- 계층 구조 생성: 계층적 클러스터링 과정을 반복하여 클러스터 간의 계층 구조를 형성합니다. 이 구조는 클러스터 간의 관계를 나타내며, 트리 구조로 표현됩니다.
- 계층적 구조 시각화: 계층적 클러스터링 결과를 시각화하여 계층 구조를 살펴볼 수 있습니다. 이를 통해 클러스터 간의 관계와 유사성을 이해할 수 있습니다.

Spectral Clustering
- 스펙트럴 클러스터링(Spectral Clustering)은 데이터를 클러스터로 그룹화하는 비지도 학습 알고리즘 중 하나입니다. 이 알고리즘은 데이터의 유사성을 고려하여 데이터를 그래프 형태로 표현하고, 그래프에서 고유한 고유벡터(eigenvector)와 고윳값(eigenvalue)을 추출하여 클러스터링을 수행합니다. 스펙트럴 클러스터링은 선형으로 구분되지 않는 데이터에 특히 유용하며, 복잡한 데이터 구조에서 클러스터링을 수행할 수 있습니다.
Minimum Cut Method
- Graph를 A와 B라는 Subgraph로 나눌 때 끊어지는 엣지들의 가중치가 최소가 되도록 하는 방법
Spectral Clustering의 원리
- 무방향 가중치 그래프(Undirected Weighted Graph): 스펙트럴 클러스터링에서는 데이터를 무방향 가중치 그래프로 표현합니다. 이 그래프는 노드(데이터 포인트)와 엣지(연결)로 이루어져 있으며, 각 엣지에는 가중치가 할당됩니다.
- Graph 구축: 인접행렬(Adjacency Matrix)을 만들기 위해 데이터 포인트 간의 유사도를 계산하여 그래프를 구축합니다. 가우시안 커널 등의 유사도 측정 방법을 사용할 수 있습니다.
- Fully Connected Graph: Fully connected graph란 모든 노드(데이터 포인트)가 엣지로 연결돼 있는 그래프를 의미합니다. 이는 모든 데이터 포인트 간의 관계를 고려한 그래프입니다.
- ε-neighborhood graph: ε-neighborhood graph는 거리가 ε보다 가까운 엣지들만 유지하고 나머지는 제거하는 그래프입니다. 이는 노드의 밀도가 높은 지역에선 많은 엣지가 형성되고, 낮은 밀도 지역에선 거의 엣지가 없는 형태를 가집니다.
- K-NN Graph: K-NN Graph는 각 노드를 주변 k개 이웃들과 연결하고 나머지 엣지는 제거하는 그래프입니다. 이는 각 데이터 포인트 주변에 가장 가까운 이웃들을 고려하여 그래프를 형성합니다.
- ε-neighborhood 그래프와 K-NN 그래프의 결합: 일반적으로는 먼저 ε-neighborhood 그래프를 구축한 뒤, K-NN Graph를 적용하여 엣지가 없는 노드도 연결하는 방식을 사용합니다. 이렇게 하면 노드 간의 관계를 더 잘 반영할 수 있습니다.
- Minimum Spanning Tree: 그래프 구축 후에도 군집 사이에 연결이 안 되는 경우가 있을 수 있는데, 이럴 때는 Minimum Spanning Tree(MST) 방법을 사용하여 연결을 시도합니다. MST는 그래프의 모든 노드를 최소 비용으로 연결하는 트리를 찾는 방법으로, 스펙트럴 클러스터링에서 군집 간의 연결을 보장하기 위해 사용됩니다. Spanning Tree는 모든 정점들이 연결되어 있어야 하고 사이클을 포함해서는 안됩니다.

DBSCAN
- DBSCAN(Density-Based Spatial Clustering of Applications with Noise)은 밀도 기반 클러스터링 알고리즘으로, 데이터의 밀도를 고려하여 클러스터를 형성하는 데 사용됩니다. 이 알고리즘은 데이터의 분포가 불균일하거나 클러스터의 모양이 다양한 경우에 효과적으로 작동합니다.
DBSCAN의 원리
- 초기화: DBSCAN은 시작점을 선택하지 않고 데이터 포인트를 모두 방문하면서 클러스터링을 수행합니다.
- 핵심 포인트(Core Point) 찾기: 주어진 데이터 포인트에서 일정 거리(epsilon, ε) 내에 최소 개수(MinPts)의 이웃 데이터 포인트가 있으면 해당 데이터 포인트를 핵심 포인트로 간주합니다. 이 거리 내의 이웃 데이터 포인트를 이웃 포인트(Neighbor Points)라고 부릅니다.
- 핵심 포인트를 중심으로 클러스터 생성: 핵심 포인트와 그 이웃 포인트를 연결하여 클러스터를 형성합니다. 이웃 포인트 또한 핵심 포인트로 간주됩니다. 따라서 핵심 포인트와 이웃 포인트가 하나의 클러스터를 형성하게 됩니다.
- 클러스터 확장: 핵심 포인트와 그 이웃 포인트가 하나의 클러스터를 형성한 후, 그 이웃 포인트의 이웃 포인트도 같은 클러스터에 추가됩니다. 이 과정은 재귀적으로 진행되며, 클러스터가 계속 확장됩니다.
- 노이즈 포인트(Noise Point) 식별: 핵심 포인트가 아니면서 이웃 포인트가 MinPts보다 작은 데이터 포인트는 노이즈 포인트로 간주됩니다. 이러한 데이터 포인트는 어떤 클러스터에 속하지 않습니다.

HDBSCAN
- HDBSCAN(Hierarchical Density-Based Spatial Clustering of Applications with Noise)은 밀도 기반 클러스터링 알고리즘의 한 변종으로, 밀도에 기반하여 데이터를 클러스터로 그룹화하는 데 사용됩니다. HDBSCAN은 DBSCAN(Density-Based Spatial Clustering of Applications with Noise)의 확장 버전으로, 클러스터의 계층적 구조를 탐지하고 이해하는 데 도움을 줍니다.
- 공간 변환 (Transform the space according to the density/sparsity): 데이터 포인트의 공간을 밀도 또는 희소성에 따라 변환합니다. 이는 데이터의 분포를 고려하여 밀도가 높은 지역과 낮은 지역을 나누는 데 도움을 줍니다.
- 가중치 그래프의 최소 신장 트리 생성 (Build the minimum spanning tree of the distance weighted graph): 거리에 가중치를 부여한 그래프에서 최소 신장 트리(Minimum Spanning Tree)를 생성합니다. 최소 신장 트리는 모든 노드를 최소 비용으로 연결하는 트리를 의미합니다.
- 연결된 구성 요소의 클러스터 계층 생성 (Construct a cluster hierarchy of connected components): 최소 신장 트리를 기반으로 연결된 구성 요소(Connected Components) 간의 클러스터 계층을 생성합니다. 이 단계에서 클러스터 간의 계층적 관계를 고려하여 트리 구조를 형성합니다.
- 최소 클러스터 크기에 따른 클러스터 계층 축소 (Condense the cluster hierarchy based on minimum cluster size): 최소 클러스터 크기를 고려하여 클러스터 계층을 축소합니다. 이는 작은 클러스터를 노이즈로 처리하거나 무시하는 데 도움을 줍니다.
- 안정된 클러스터 추출 (Extract the stable clusters from the condensed tree): 클러스터 계층에서 안정된 클러스터를 추출합니다. 이러한 안정된 클러스터는 최종적으로 HDBSCAN 알고리즘의 결과로 반환되며, 데이터의 클러스터링 패턴을 나타냅니다.
Clustering의 결과 평가 지표( 크게 3개의 카테고리)
- External : 우리가 알고 있는 정답(Label)과 비교해 봄 (있을 수 없음)
- Internal : Cluster들의 공간들을 확인해 보는 방법
- Relative : Cluster의 공간과 Cluster들 간 떨어진 정도를 가지고 판단할 수 있음
Clustering Methods
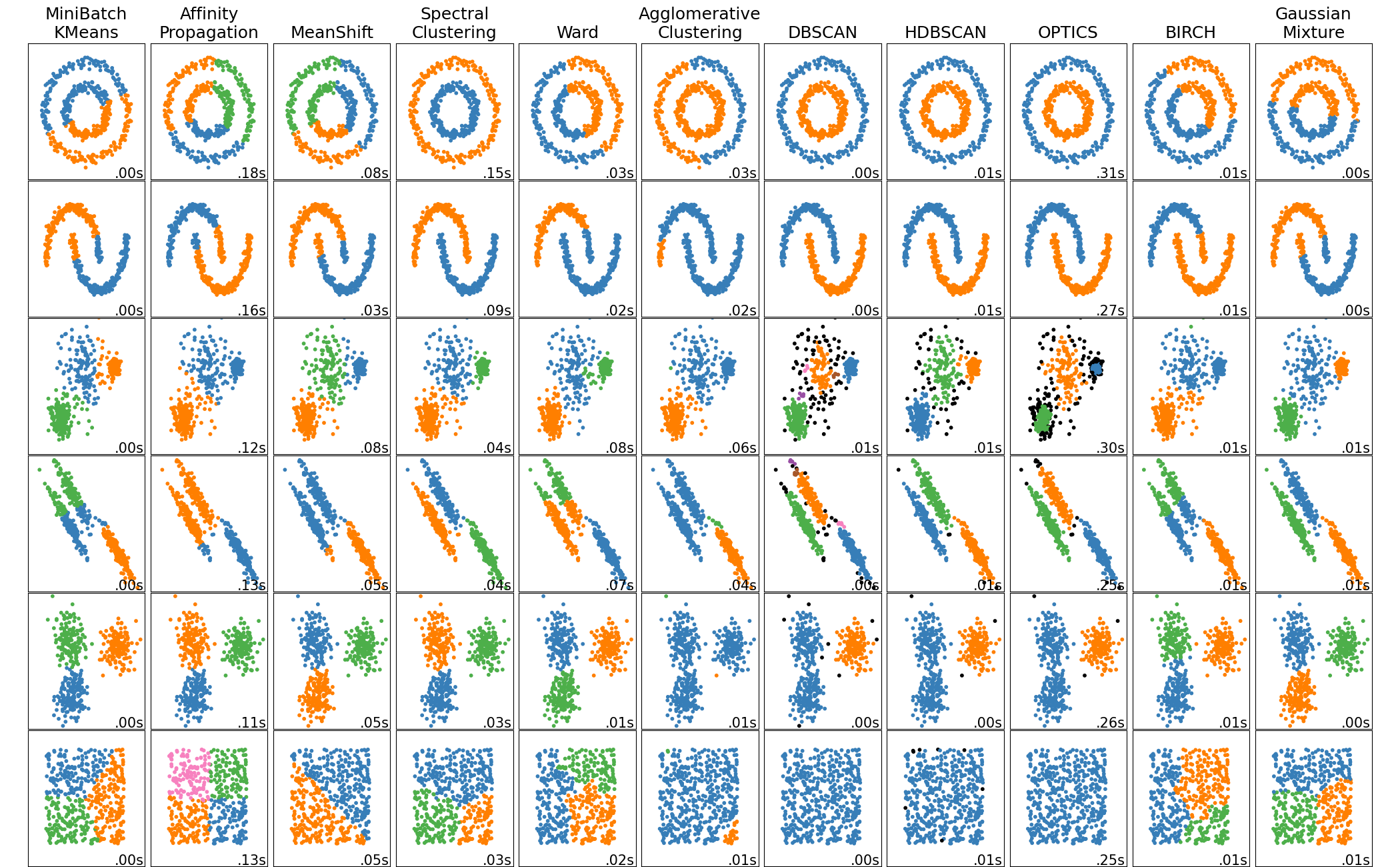
[마무리]
오늘도 새로운 개념들에 대해서 수업을 들었습니다. 수업을 다 듣고 정리하면 그래도 어느 정도 이해되는 것 같은데 다음날이 되면 뭔가 다시 리셋이 되는 거 같은 느낌을 받았습니다. 복습도 중요한 거 같고 실습을 통해서 많이 알고리즘들을 사용해 보는 것도 중요한 거 같습니다. 꾸준히 하다 보면 분명히 익숙해지고 능숙해질 거라는 마음으로 계속 열심히 해야 될 거 같습니다.
'AI > 머신러닝' 카테고리의 다른 글
| [AI 부트캠프] DAY 51 - 머신러닝 6 (0) | 2023.09.27 |
|---|---|
| [AI 부트캠프] DAY 50 - 머신러닝 5 (0) | 2023.09.26 |
| [AI 부트캠프] DAY 49 - 머신러닝 4 (0) | 2023.09.23 |
| [AI 부트캠프] DAY 47 - 머신러닝 2 (0) | 2023.09.21 |
| [AI 부트캠프] DAY 46 - 머신러닝 1 (0) | 2023.09.20 |




댓글