[오늘의 일지]
파이썬 EDA 실시간 강의 - 공공데이터로 EDA 해보기, 타이타닉 데이터로 EDA 해보기
[상세 내용]
파이썬 EDA
공공데이터로 EDA 해보기
- 어제 사용했던 공공데이터 상권분석 자료를 이용해서 마저 남아 있던 주제의 분석을 마무리해 보겠습니다. 주제는 아래에 나와 있습니다.
- 한식 음식점들이 많이 사용하는 단어 찾아보기
'많이 사용하는'이라는 말을 다르게 표현하자면 빈도분석이라고 하는데요. 빈도를 분석하기 위해서는 일단 각각 전국단위로 분리되어 있는 데이터를 하나로 묶어주는 것이 중요합니다. 이 과정은 어제 진행했었는데 다시 해보겠습니다. 여기서 데이터 파일을 불러올 때 glob()이라는 라이브러리가 유용하게 사용됩니다. glob()은 원하는 폴더 안에 존재하는 파일들 중 원하는 단어를 포함하는 파일들의 이름을 가진 모든 파일들의 이름을 리스트 형식으로 반환하는 역할을 합니다. 예시로 살펴보자면 glob() 안에 glob('./data/상가(상권) 정보_20230630/*.csv') 이런 형식으로 사용해 주면 폴더명 다음의 '/'이하에 '*'와 함께 원하는 단어를 포함한 즉 '.csv'를 포함한 모든 파일명을 리스트 형식으로 반환해 줍니다.
file_list = sorted(glob('./data/상가(상권)정보_20230630/*.csv'))
file_list
>>>
['./data/상가(상권)정보_20230630\\소상공인시장진흥공단_상가(상권)정보_강원_202306.csv',
'./data/상가(상권)정보_20230630\\소상공인시장진흥공단_상가(상권)정보_경기_202306.csv',
'./data/상가(상권)정보_20230630\\소상공인시장진흥공단_상가(상권)정보_경남_202306.csv',
'./data/상가(상권)정보_20230630\\소상공인시장진흥공단_상가(상권)정보_경북_202306.csv',
'./data/상가(상권)정보_20230630\\소상공인시장진흥공단_상가(상권)정보_광주_202306.csv',
'./data/상가(상권)정보_20230630\\소상공인시장진흥공단_상가(상권)정보_대구_202306.csv',
'./data/상가(상권)정보_20230630\\소상공인시장진흥공단_상가(상권)정보_대전_202306.csv',
'./data/상가(상권)정보_20230630\\소상공인시장진흥공단_상가(상권)정보_부산_202306.csv',
'./data/상가(상권)정보_20230630\\소상공인시장진흥공단_상가(상권)정보_서울_202306.csv',
'./data/상가(상권)정보_20230630\\소상공인시장진흥공단_상가(상권)정보_세종_202306.csv',
'./data/상가(상권)정보_20230630\\소상공인시장진흥공단_상가(상권)정보_울산_202306.csv',
'./data/상가(상권)정보_20230630\\소상공인시장진흥공단_상가(상권)정보_인천_202306.csv',
'./data/상가(상권)정보_20230630\\소상공인시장진흥공단_상가(상권)정보_전남_202306.csv',
'./data/상가(상권)정보_20230630\\소상공인시장진흥공단_상가(상권)정보_전북_202306.csv',
'./data/상가(상권)정보_20230630\\소상공인시장진흥공단_상가(상권)정보_제주_202306.csv',
'./data/상가(상권)정보_20230630\\소상공인시장진흥공단_상가(상권)정보_충남_202306.csv',
'./data/상가(상권)정보_20230630\\소상공인시장진흥공단_상가(상권)정보_충북_202306.csv']
- 그럼 이제 모든 파일명이 담긴 리스트를 이용해서 나눠져 있는 전국 데이터를 하나로 만드는 과정을 진행해 보겠습니다. for문을 이용해서 전국 데이터 파일 리스트를 판다스의 csv 읽기 함수를 이용해서 읽어낸 다음 판다스의 concat함수를 이용해서 데이터를 하나씩 붙여주면 마무리됩니다.
# 데이터들을 불러와봅시다.
# 함수의 파라미터로 파일 이름 규칙을 주면, 규칙에 해당하는 파일 이름을 모두 가져오는 함수.
file_list = sorted(glob('./data/상가(상권)정보_20230630/*.csv'))
file_list
data = pd.DataFrame()
for file in tqdm(file_list):
temp = pd.read_csv(file)
data = pd.concat([data,temp], axis=0)
data
>>>
상가업소번호 상호명 지점명 상권업종대분류코드 상권업종대분류명 상권업종중분류코드 상권업종중분류명 상권업종소분류코드 상권업종소분류명 표준산업분류코드 ... 건물관리번호 건물명 도로명주소 구우편번호 신우편번호 동정보 층정보 호정보 경도 위도
0 MA0101202210A0084547 금강산노래광장 NaN I2 음식 I211 주점 I21101 일반 유흥 주점 I56211 ... 4217010300007470000000086 파크장 강원특별자치도 동해시 송정로 11 240806 25789 NaN 지 NaN 129.127525 37.495265
1 MA010120220805430826 에이치속눈썹수강아카데미 NaN S2 수리·개인 S207 이용·미용 S20702 피부 관리실 S96113 ... 4211039021110620001000001 NaN 강원특별자치도 춘천시 동내면 외솔길19번길 80-36 200883 24401 NaN NaN NaN 127.758764 37.857831
2 MA010120220805430903 엔젤 NaN I2 음식 I201 한식 I20101 백반/한정식 I55109 ... 4277032022103660000008290 NaN 강원특별자치도 정선군 남면 민둥산로 175-13 233837 26148 NaN NaN NaN 128.792089 37.259788
3 MA010120220805430941 누베헤어 NaN S2 수리·개인 S207 이용·미용 S20701 미용실 S96112 ... 4211012500100440010000008 춘천파크자이 강원특별자치도 춘천시 스포츠타운길 458 200200 24472 NaN 3 NaN 127.707653 37.867744
4 MA010120220805430946 공차 NaN I2 음식 I212 비알코올 I21201 카페 I56229 ... 4213033023113500001000001 NaN 강원특별자치도 원주시 지정면 신지정로 211 220821 26354 NaN NaN NaN 127.872713 37.374189
... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ...
81718 MA0101202303A0020503 꽃개 NaN G2 소매 G220 애완동물·용품 소매 G22001 애완동물/애완용품 소매업 G47852 ... 4377033021106020004000001 NaN 충청북도 음성군 맹동면 덕금로 236 369811 27733 NaN NaN NaN 127.546988 36.925111
81719 MA0101202303A0014518 만두를빚다 NaN I2 음식 I210 기타 간이 I21007 김밥/만두/분식 I56111 ... 4311110300100960017052823 NaN 충청북도 청주시 상당구 중앙로 28-1 360012 28543 NaN 1 NaN 127.488871 36.639523
81720 MA0101202303A0107065 골목식당 NaN I2 음식 I201 한식 I20101 백반/한정식 I56111 ... 4375025024104780038023581 NaN 충청북도 진천군 진천읍 중앙서로 10-1 365807 27831 NaN NaN NaN 127.442060 36.859096
81721 MA0101202303A0033503 씨유옥천청산점 NaN G2 소매 G204 종합 소매 G20405 편의점 G47122 ... 4373035021100850007007997 NaN 충청북도 옥천군 청산면 지전1길 3 373874 29013 NaN 2 NaN 127.792482 36.344138
81722 MA0101202303A0033505 카페지아니 NaN I2 음식 I212 비알코올 I21201 카페 I56221 ... 4374525028101720000006486 NaN 충청북도 증평군 증평읍 문화로 62 368904 27933 NaN NaN NaN 127.590042 36.784990
2417759 rows × 39 columns
- courpus : 이제 합쳐진 데이터에서 주제였던 '한식'을 키워드로 가져와야 합니다. 한식'을 가져오는 것은 mask처리해서 loc함수를 이용하면 어렵지 않게 가져올 수 있습니다. 상호명은 그냥 lod함수로 가져오면 됩니다. 이렇게 상호명을 추출하는 것을 일종에 corpus라고 하는데요. corpus라는 단어는 특정한 목적을 가지고 언어의 표본을 추출한 집합이라는 의미를 가지고 있습니다.
# corpus
corpus = data.loc[data['상권업종중분류명'] == '한식', '상호명']
corpus
>>>
2 엔젤
10 태능갈비
12 박차닭갈비
14 남경막국수
27 먹자골
...
81700 다정정육식당
81710 충남순대
81711 장어92번지
81717 일등식당
81720 골목식당
Name: 상호명, Length: 322709, dtype: object
- tokenization : 사실 tokenization를 하기 전에 text cleaning이라고 하는 것을 실행해야 하는데 정확하게 단어를 뽑아내려면 문장을 정규 표현식을 사용해서 일일이 불용어를 제거하는 등 해야 하는 작업이 생각보다 오래 걸려서 생략하고 그냥 라이브러리를 이용하는 tokenization라는 형태소 분석기라는 의미를 가지고 있는 이것을 사용하게 되었습니다. 보통 여러 가지 라이브러리를 사용할 수 있지만 파이썬에서는 pecab을 사용하였습니다. 사용 예시로는 위에서도 나와 있듯이 상호명에 나오는 음식을 분리시켜서 빈도수를 알아보기 위함입니다. 그럼 pecab의 예시를 알아보겠습니다.
# pecab : Mecab의 python Version
from pecab import PeCab
pecab = PeCab()
# 모든 단위를 짤라주는 것 뿐만 아니라 품사까지 알려주는 함수 pos
pecab.pos('아버지가방에들어가신다.')
>>>
[('아버지', 'NNG'),
('가', 'JKS'),
('방', 'NNG'),
('에', 'JKB'),
('들어가', 'VV'),
('신다', 'EP+EF'),
('.', 'SF')]
# 모든 단위를 짤라주는 함수 morphs
pecab.morphs('아버지가방에들어가신다.')
>>>
['아버지', '가', '방', '에', '들어가', '신다', '.']
# 단위로 짜르고 명사만을 분리해서 출력하는 nouns
pecab.nouns('아버지가방에들어가신다.')
>>>
['아버지', '방']
- 이제 상호명을 분리해서 저장한 corpus를 tokenization 해 보겠습니다. 생각보다 시간이 오래 걸렸습니다.
tokenized_corpus = []
for doc in tqdm(corpus):
tokenized_corpus.append(pecab.nouns(doc))
tokenized_corpus
>>>
[['엔젤'],
['갈비'],
['닭갈비'],
['남경', '막국수'],
['골'],
['아리랑', '산촌', '식당'],
['인구', '시장'],
['밥집'],
['홍천', '해물', '찜'],
['원조', '남원주'],
['이모', '한식'],
['영랑', '해변', '장어', '꿈'],
['강남', '교자'],
['황토', '집'],
['돼지'],
...]
# 근데 위에 리스트는 리스트 안에 또 리스트가 있는 구조라
# 안에 리스트를 제거하는 과정을 거쳐야 Counter 모듈을 사용할 수 있습니다.
total_tokens = []
for tokens in tqdm(tokenized_corpus):
total_tokens = total_tokens + tokens # concatenation
total_tokens
>>>
['엔젤',
'갈비',
'닭갈비',
'남경',
'막국수',
'골',
'아리랑',
'산촌',
'식당',
'인구',
'시장',
'밥집',
'홍천',
'해물',
'찜',
'원조',
'남원주',
'이모',
'한식',
'영랑',
'해변',
'장어',
'꿈',
'강남',
'교자',
'황토',
'집',
'돼지',
...]
- modeling : 리스트화된 키워드들을 숫자와 함께 정리할 수 있는데 collections 라이브러리의 Counter 모듈을 사용하면 됩니다.
# modeling
from collections import Counter
counter = Counter(total_tokens)
counter.most_common(30)
>>>
[('식당', 32712),
('집', 12613),
('족발', 7024),
('점', 6986),
('칼국수', 6333),
('갈비', 5983),
('찜', 5945),
('횟집', 5370),
('푸드', 5214),
('곱창', 4833),
('삼', 4778),
('국밥', 4758),
('돈', 4268),
('밥', 4171),
('고기', 4148),
('돼지', 3898),
('닭', 3741),
('국수', 3608),
('감자탕', 3501),
('밥상', 3497),
('구이', 3435),
('해장국', 3435),
('순대', 3353),
('추어탕', 2933),
('대국', 2849),
('왕', 2830),
('숯불', 2756),
('닭갈비', 2750),
('골', 2740),
('한우', 2687)]
- 마지막으로 wordcloud 라이브러리를 이용해서 키워드의 개수 별로 단어의 크기를 나타내 주는 지표를 완성하면 끝나게 됩니다.
import matplotlib
import matplotlib.font_manager as fm
#plt.rc('font',family='AppleGothic')
# font_location = '/System/Library/Fonts/AppleSDGothicNeo.ttc'
font_location = 'C:/Windows/Fonts/Malgun.ttf' # For Windows
font_name = fm.FontProperties(fname=font_location).get_name()
print(font_name)
matplotlib.rc('font', family=font_name)
from wordcloud import WordCloud
wc = WordCloud(font_path=font_location, # 사용하는 글꼴의 경로
max_words=100, # 최대 몇개의 단어를 사용할지 (빈도순)
width=1920, # 가로 길이
height=1080, # 세로 길이
random_state=42, # for reproducing
background_color='white', # 배경 색, 기본이 검정.
colormap='viridis' # color palette
).generate_from_frequencies(counter)
plt.axis('off')
plt.savefig('./wordcloud.png')
plt.imshow(wc)
타이타닉 데이터로 EDA 해보기
- 타이타닉 자료는 지난 수업에도 많이 사용했는데 오늘의 주제는 아래와 같습니다.
- 타이타닉 생존자와 상관관계가 높은 요소 찾기
- 타이타닉 데이터를 불러와서 결측치가 있는지 조사합니다.(원래 데이터 분석을 할 때 이행해야 하는 디폴트값과 같은 과정이라고 설명해 주셨습니다.)
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
# train.csv 파일 불러오기
titanic = pd.read_csv('./data/titanic/train.csv')
titanic
# 결측치가 존재하는지
titanic[titanic.isnull().any(axis=1)]
- 이번 상관관계를 알아보는 과정에서는 결측치를 크게 신경 쓰지 않았던 거 같습니다. 그런 뒤 dtype을 이용해서 object인 칼럼을 찾았습니다. 그리고 생존 비율을 알아봤습니다.(여기까지가 디폴트값이라고 하셨습니다. 총 정리하자면 첫 번째 결측지가 존재하는지 파악하기, 두 번째 object 타입을 가지는 칼럼이 존재하는지, 마지막으로 타깃의 값의 분배비율을 알아보는 것 까지가 데이터 분석의 디폴드값처럼 이행되는 초기 단계라고 하셨습니다.)
# dtype이 object인 column이 있는지
titanic.columns[titanic.dtypes == 'object']
>>>
Index(['Name', 'Sex', 'Ticket', 'Cabin', 'Embarked'], dtype='object')
# target value의 distribution이 어떻게 되는지
titanic.Survived.value_counts()
sns.countplot(data=titanic, x='Survived')
>>>
- 상관계수를 corr함수로 구하고 heatmap 만들기 (생존자와 관련이 깊은 칼럼은 'Pclass'와 'Fare'으로 좌석의 클래스와 요금인데요. 역시 생존율과 경제적 지위가 비교적 관련이 높았던 것으로 판단이 됩니다. )
# correlation matrix heatmap
corr = titanic.corr()
corr
>>>
PassengerId Survived Pclass Age SibSp Parch Fare
PassengerId 1.000000 -0.005007 -0.035144 0.036847 -0.057527 -0.001652 0.012658
Survived -0.005007 1.000000 -0.338481 -0.077221 -0.035322 0.081629 0.257307
Pclass -0.035144 -0.338481 1.000000 -0.369226 0.083081 0.018443 -0.549500
Age 0.036847 -0.077221 -0.369226 1.000000 -0.308247 -0.189119 0.096067
SibSp -0.057527 -0.035322 0.083081 -0.308247 1.000000 0.414838 0.159651
Parch -0.001652 0.081629 0.018443 -0.189119 0.414838 1.000000 0.216225
Fare 0.012658 0.257307 -0.549500 0.096067 0.159651 0.216225 1.000000
sns.heatmap(data=corr, annot=True, fmt='.3f', cmap='Reds')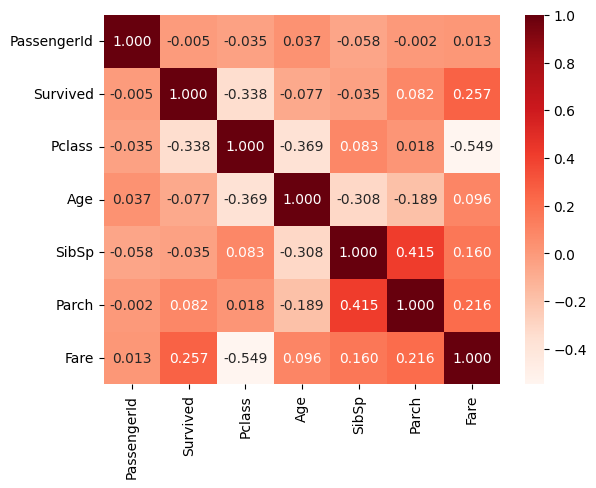
[마무리]
오늘도 어제에 이어서 여러 가지 EDA를 실행했습니다. 오늘은 비교적 많은 양의 데이터를 하나로 전처리하는 과정이 있었습니다. 그 과정에서 여러 가지 느낀 것들이 있습니다. 많은 양의 데이터를 사용하기 위해서는 컴퓨터의 사양도 중요하다는 것과 생각보다 데이터를 다루는 것이 오래 걸리는 작업이라는 것을 느꼈습니다. 머신러닝 과정도 시간이 꽤 걸리는 과정들이 많다고 들었는데 벌써부터 걱정되고 기대도 되는 것 같습니다.
'AI > 데이터 사이언스' 카테고리의 다른 글
| [AI 부트캠프] DAY 29 - 파이썬 EDA 9 (0) | 2023.08.26 |
|---|---|
| [AI 부트캠프] DAY 28 - 파이썬 EDA 8 (0) | 2023.08.25 |
| [AI 부트캠프] DAY 26 - 파이썬 EDA 6 (2) | 2023.08.23 |
| [AI 부트캠프] DAY 25 - 파이썬 EDA 5 (0) | 2023.08.22 |
| [AI 부트캠프] DAY 24 - 파이썬 EDA 4 (0) | 2023.08.19 |




댓글