[오늘의 일지]
파이썬 응용하기 - 크롤링, 다양한 API 활용
[상세 내용]
파이썬 응용하기
크롤링
- 네이버 크롤링해 보기
- 원하는 페이지 파악하기
- url 파악하기
https://news.naver.com/main/list.naver?mode=LSD&mid=sec&sid1=105&date=20230803
예를 들면 위에 같이 it/과학의 최신 뉴스들을 모아둔 페이지가 있다고 합니다.
페이지의 맨 아래쪽으로 내려가서 날짜와 페이지를 몇 번 눌러보면 url이 특정 구조를 가지고 있다는 것을 알 수 있습니다.
https://news.naver.com/main/list.naver?mode=LSD&mid=sec&sid1=105&date=20230803
위에 주소처럼 날짜와 페이지를 변경만 하면 그날의 뉴스를 파악할 수 있었습니다. 파악한 날짜와 페이지만 변경하면 원하는 날짜의 뉴스 기사들을 파싱 하기에 좋습니다.

- html 파악하기
개발자 도구를 이용해서 각 기사의 제목과 요약 내용 그리고 신문사와 날짜 등 원하는 부분의 html 코드를 확인할 수 있습니다.
기사를 눌러보니 <ul> 태그 안에 있는 'type06_headline'라는 클래스에 있는 것까지 확인이 됩니다.

- 그럼 본격적으로 네이버 크롤링을 시작하겠습니다.
네이버는 자체적으로 크롤링을 방지하기 위한 로직을 가지고 있기 때문에 우회를 해서 정보를 받아와야 됩니다.
import requests
headers = {'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36'}
url = 'https://news.naver.com/main/list.naver?mode=LSD&mid=sec&sid1=105&date=20230803'
response = requests.get(headers=headers, url=url)
print(response.text)
(여기서 새롭게 알게 된 사실은 뉴스 페이지에서 블라인드라고 처리된 부분은 파싱 되지 않는 것처럼 보였습니다. 가져오기 했을 때 빈 리스트로 나와서 당황했습니다.)
- BeautifulSoup 이용해서 파싱하고 원하는 기사 제목 텍스트로 추출하기
import requests
from bs4 import BeautifulSoup
# requests 모듈을 통해서 요청보내고, html 문서받기
headers = {'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36'}
url = 'https://news.naver.com/main/list.naver?mode=LSD&mid=sec&sid1=105&date=20230803'
response = requests.get(headers=headers, url=url)
# 파싱하기
soup = BeautifulSoup(response.text, 'html.parser')
# 원하는 정보 선택하기
news = soup.select('.type06_headline li dl')
print(news)
vscode에서 불러오기가 잘 되는 것을 확인할 수 있었습니다.
- 뉴스 기사 제목만 10개 출력하기
import requests
from bs4 import BeautifulSoup
# requests 모듈을 통해서 요청보내고, html 문서받기
headers = {'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36'}
url = 'https://news.naver.com/main/list.naver?mode=LSD&mid=sec&sid1=105&date=20230803'
response = requests.get(headers=headers, url=url)
# 파싱하기
soup = BeautifulSoup(response.text, 'html.parser')
# 원하는 정보 선택하기
news_list = soup.select('.type06_headline li dl')
for news in news_list:
try:
print(news.select('a')[1].text.strip())
except IndexError:
print(news.select('a')[0].text.strip())
- 기사와 신문사 같이 추출
import requests
from bs4 import BeautifulSoup
# requests 모듈을 통해서 요청보내고, html 문서받기
headers = {'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36'}
url = 'https://news.naver.com/main/list.naver?mode=LSD&mid=sec&sid1=105&date=20230803'
response = requests.get(headers=headers, url=url)
# 파싱하기
soup = BeautifulSoup(response.text, 'html.parser')
# 원하는 정보 선택하기
news_list = soup.select('.type06_headline li dl')
for news in news_list:
try:
print(news.select('a')[1].text.strip())
except IndexError:
print(news.select('a')[0].text.strip())
print(news.select('.writing')[0].text)
- 빈 리스트를 만들어놓고, 거기에 [제목, 신문사 이름] 형태의 리스트를 계속 추가해 놓는 형태로 데이터를 만들어놓기
import requests
from bs4 import BeautifulSoup
# requests 모듈을 통해서 요청보내고, html 문서받기
headers = {'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36'}
url = 'https://news.naver.com/main/list.naver?mode=LSD&mid=sec&sid1=105&date=20230803'
response = requests.get(headers=headers, url=url)
# 파싱하기
soup = BeautifulSoup(response.text, 'html.parser')
# 원하는 정보 선택하기
result_list = [] # 결과 리스트
news_list = soup.select('.type06_headline li dl')
for news in news_list:
try:
title = news.select('a')[1].text.strip()
except IndexError:
title = news.select('a')[0].text.strip()
writing = news.select('.writing')[0].text
result_list.append([title, writing]) # 결과 리스트에 [제목, 신문사] 추가
print(result_list)
- 저장된 리스트를 csv 파일로 만들기
여기서는 csv 패키지를 사용합니다.
import requests
import csv # csv 패키지 불러오기
from bs4 import BeautifulSoup
# requests 모듈을 통해서 요청보내고, html 문서받기
headers = {'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36'}
url = 'https://news.naver.com/main/list.naver?mode=LSD&mid=sec&sid1=105&date=20230803'
response = requests.get(headers=headers, url=url)
# 파싱하기
soup = BeautifulSoup(response.text, 'html.parser')
# 원하는 정보 선택하기
result_list = [] # 결과 리스트
news_list = soup.select('.type06_headline li dl')
for news in news_list:
try:
title = news.select('a')[1].text.strip()
except IndexError:
title = news.select('a')[0].text.strip()
writing = news.select('.writing')[0].text
result_list.append([title, writing]) # 결과 리스트에 [제목, 신문사] 추가
with open('news.csv', 'a', encoding='utf-8-sig') as f: # news.csv 파일을 내용 추가가 가능한 형태로 열기
writer = csv.writer(f) # csv 모듈 속 쓰기 역할을 담당하는 객체를 생성
writer.writerows(result_list) # 해당 객체를 이용해 위 리스트를 저장
print(result_list)
- 또 다른 크롤링 방식 (Selenium)
클릭과 같은 상호작용이 이루어지기 전에는 우리가 원하는 정보를 받아올 수 없는 사이트들이 존재합니다. 이런 경우에는 앞서 살펴본 것과 같은 방식대로 단순히 주소와 HTML 구조만 파악해서는 크롤링을 할 수 없습니다. 그래서 Selenium을 이용해서 크롤링하는 방법이 있습니다. Selenium 동작을 이용해서 원하는 페이지에 접근해서 페이지에 있는 html 소스를 가져오는 방식입니다.
- 사용 방법
- 요소 하나 찾기 - driver.find_element(By.CSS_SELECTOR, '태그, 선택자')
- 요소 여러개 찾기 - driver.find_elements(By.CSS_SELECTOR, '태그, 선택자')
- 글자 입력하기 - 요소.send_keys(’단어’)
- 요소 클릭하기 - 요소.click()
- 특정한 요소가 로딩될 때까지 기다리기 - WebDriverWait(driver, 초).until(EC.presence_of_element_located((By.CSS_SELECTOR, ‘태그, 선택자’)))
- 그냥 기다리기 - time.sleep(초)
- 현재 페이지의 HTML 다 가져오기 - driver.page_source
- 네이버 홈페이지에 접근해서 검색창에 'odds-endz'검색 후 검색한 페이지의 소스를 가져오는 코드 예시
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from bs4 import BeautifulSoup
# 크롬 드라이버 실행 파일이 어디있는지 위치 명시
# 지금은 같은 경로에 있기 때문에, () 안에 아무것도 명시하지 않아도 무방
driver = webdriver.Chrome()
# 어떤 주소로 크롬 브라우저가 접속할 건지 지정
driver.get('https://naver.com')
# 검색창이 로딩되어서 나타날때까지 최대 '10초'까지 대기 (우리가 찾고자 하는 요소가 나타나면 바로 대기를 중단하고 다음 코드 실행)
WebDriverWait(driver, 10).until(EC.presence_of_element_located((By.CSS_SELECTOR, '#query')))
# 검색창 요소 특정
search_input = driver.find_element(By.CSS_SELECTOR, '#query')
search_input.send_keys('odds-endz') # 검색하도록 지시
# 검색 버튼 특정
search_button = driver.find_element(By.CSS_SELECTOR, '#search-btn')
search_button.click() # 클릭하도록 지시
# 현재 브라우저 상의 HTML을 변수에 저장
# time.sleep() 등으로 검색이 끝날때까지 기다린 후에 해당 페이지 html 을 저장하는 것이 더욱 정확함
html = driver.page_source
# 브라우저 종료
driver.quit()
# 이제 bs4로 해당 html을 파싱
soup = BeautifulSoup(html, 'html.parser')
# a 태그만 다 가져오기
a_elements = soup.select('.main_pack > section.sc_new.sp_ntotal._sp_ntotal._prs_sit_5po._fe_root_sit_5po > div > ul > li > div > div.total_group > div > a > div')
print(a_elements)
다양한 API 활용
- API의 개념 : API는 Application Programming Interface(애플리케이션 프로그램 인터페이스)의 줄임말입니다. API의 맥락에서 애플리케이션이라는 단어는 고유한 기능을 가진 모든 소프트웨어를 나타냅니다. 인터페이스는 두 애플리케이션 간의 서비스 계약이라고 할 수 있습니다.
- 날씨 API 사용해 보기
API 에는 이용하기 위해 키(key)가 필요한 Private API 가 있고, 누구나 사용할 수 있도록 공개된 Open (Public) API 가 있습니다. 날씨 API는 open API이므로 이용해 보겠습니다. 링크에 접속하면, 위도 경도 등을 명시해서 해당 위치의 날씨 정보를 받아올 수 있습니다.
https://open-meteo.com/en/docs#api_form
🌦️ Docs | Open-Meteo.com
Weather Forecast API Seamless integration of high-resolution weather models with up 16 days forecast
open-meteo.com
- 도시를 서울로 설정하고 url을 받습니다.
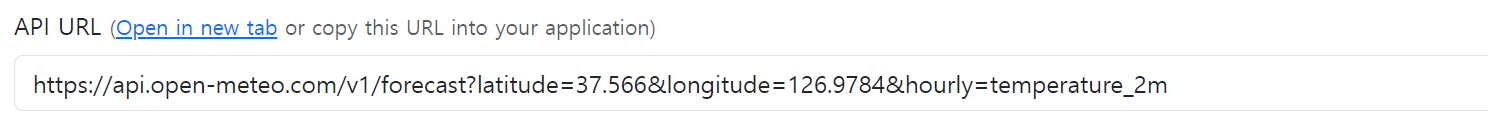
url을 통해서 사이트로 들어가면 다음과 같이 온도 정보가 나옵니다.

- 이걸 파이썬으로 가져와서 문서화해 보겠습니다.
여기서는 json 패키지와 requests를 이용합니다.
import requests
import json
response = requests.get('https://api.open-meteo.com/v1/forecast?latitude=37.566&longitude=126.9784&hourly=temperature_2m')
data = json.loads(response.text)
print(data)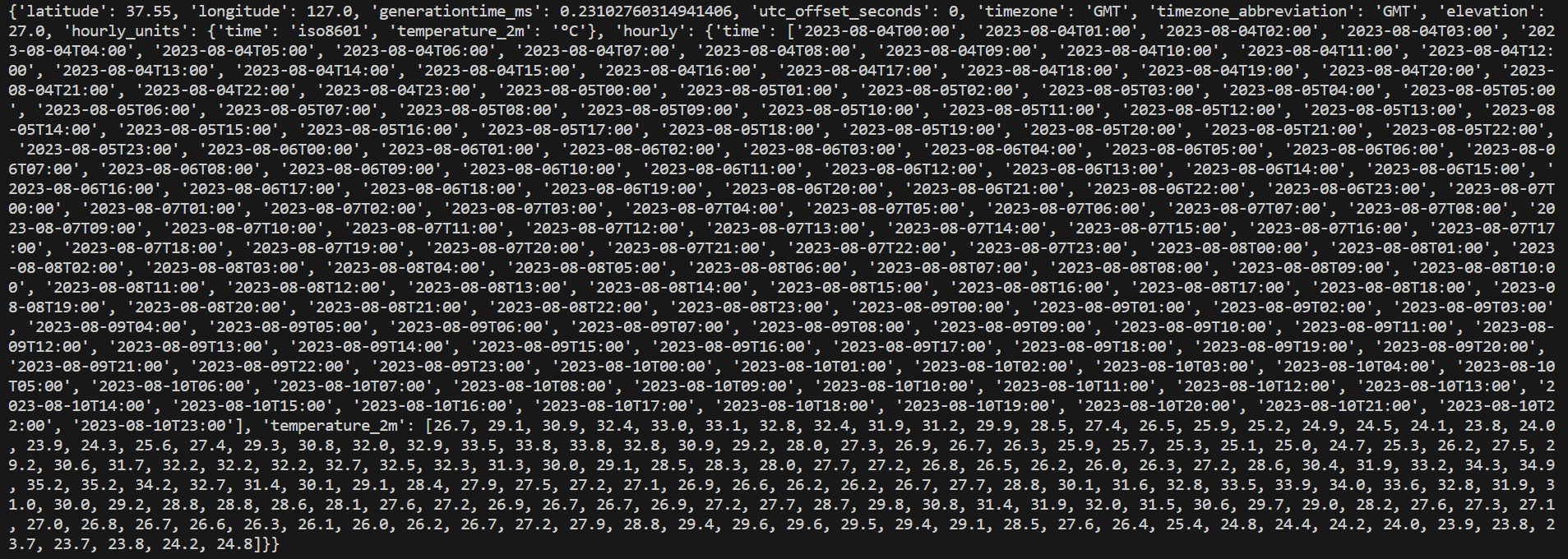
[마무리]
오늘은 어제 크롤링에 대한 수업을 이어서 마무리했고 API의 사용에 대한 것을 예시를 통해 조금씩 알아가는 과정이 진행되었습니다. 확실히 지금까지 했던 내용들과는 차이가 느껴졌던 거 같습니다. 혼자서 여러 가지 사이트를 크롤링을 하면서 연습해 보는 것이 중요한 것 같다고 느꼈습니다. 또 이렇게 한 주가 마무리되었는데 요즘 들어 느끼는 것이 정해진 스케줄 대로 공부하다 보니 시간이 빠르게 흘러가고 있다는 생각이 들었습니다. 그만큼 바쁘게 투자한 시간이 헛되지 않았으면 좋겠습니다.
'프로그래밍 > Python' 카테고리의 다른 글
| [AI 부트캠프] DAY 41 - 코딩 테스트 2 (0) | 2023.09.13 |
|---|---|
| [AI 부트캠프] DAY 40 - 코딩 테스트 1 (0) | 2023.09.12 |
| [AI 부트캠프] DAY 14 - 파이썬 8 (0) | 2023.08.04 |
| [AI 부트캠프] DAY 13 - 파이썬 7 (0) | 2023.08.03 |
| [AI 부트캠프] DAY 12 - 파이썬 6 (0) | 2023.08.02 |




댓글